
" J'ai remarqué que même les gens qui affirment que tout est prédestiné et que nous ne pouvons rien y changer regardent avant de traverser la route " Stephen Hawking
Massive external validation of a machine learning algorithm to predict pulmonary embolism in hospitalized patients
Validation externe massive d'un algorithme d'apprentissage automatique pour prédire l'embolie pulmonaire chez les patients hospitalisés
Jieru Shen, Satish Casie et coll, Thrombosis Research 216 (2022) 14–21 https://www.sciencedirect.com/science/article/pii/S0049384822002900#!
Article librev d'accès
L'embolie pulmonaire (EP) est une affection potentiellement mortelle associée à environ 10 % des décès de patients hospitalisés. Les algorithmes d'apprentissage automatique (MLA) qui prédisent l'apparition de l'embolie pulmonaire (EP) pourraient permettre un traitement plus précoce et améliorer les résultats pour les patients. Cependant, la mesure dans laquelle ils se généralisent à des populations de patients plus larges a un impact sur leur utilité clinique.
Mener la première validation externe à grande échelle d'un modèle de prédiction de l'EP basé sur l'apprentissage automatique qui utilise les données du DSE des trois premières heures du séjour à l'hôpital d'un patient pour prédire l'apparition de l'EP dans les 10 jours suivant le séjour à l'hôpital.
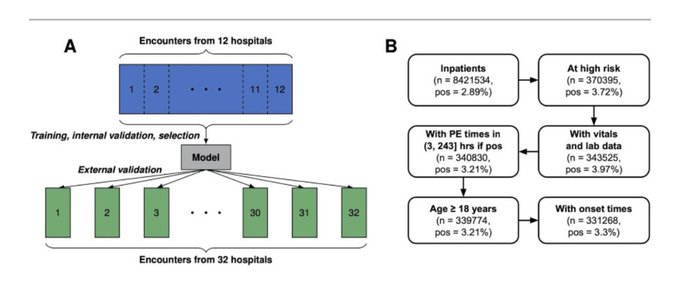
Cette étude rétrospective a inclus environ deux millions d'admissions à l'hôpital pour adultes dans 44 établissements médicaux aux États-Unis de 2011 à 2017 . un modèle XGBoost. La validation externe du modèle a été menée sur des populations de patients de chacun des 32 établissements médicaux ( n total = 1 660 715 ; 3,7 % d'EP positive) sans recyclage. Les performances du modèle ont été évaluées à l'aide de l'aire sous la courbe caractéristique de fonctionnement du récepteur (AUROC). La régression par élimination vers l'arrière a été utilisée pour identifier les corrélations entre les caractéristiques des ensembles de validation externes et AUROC.
Le modèle a bien fonctionné (AUROC = 0,87) sur le sous-ensemble d'attente de 20 % de l'ensemble d'apprentissage. Malgré des différences démographiques entre les 32 populations de validation externe (pourcentage d'EP positive : min = 1,54 %, max = 6,47 %), sans réentraînement, le modèle présentait une excellente discrimination, avec un AUROC moyen de 0,88 (min = 0,79, max = 0,93). Fixant la sensibilité à 0,80, le modèle avait une spécificité moyenne de 0,85 (min = 0,64, max = 0,93). La régression par élimination vers l'arrière a identifié une association négative (β = -0, 015, p <0, 001) entre le pourcentage de rencontres positives à la PE et AUROC.
Un modèle de prédiction de l'EP s'est remarquablement bien comporté sur 32 populations de patients externes différentes sans recyclage et malgré des différences significatives dans les caractéristiques démographiques, démontrant sa généralisabilité et son potentiel en tant qu'outil d'aide à la décision clinique pour faciliter la détection de l'EP et améliorer les résultats des patients dans un cadre clinique.
Étant donné que l'EP aiguë peut très rapidement devenir un événement potentiellement mortel, un « système d'alerte précoce » permettrait une thromboprophylaxie appropriée , dont il a été démontré qu'elle diminue le risque de décès dû à l'EP . Scores prédictifs cliniques comme le score de Caprini, le score de prédiction de Padoue et le score IMPROVE ,ont été développés pour identifier le risque de MTEV mais pas spécifiquement le risque d'EP chez les patients hospitalisés.
À notre connaissance, notre modèle est le premier outil de ML basé sur le DSE conçu pour prédire l'EP chez les patients hospitalisés.
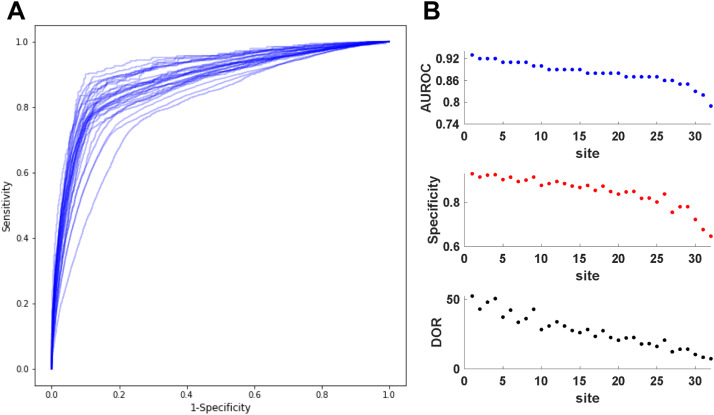
Performance du modèle eXtreme Gradient Boosting (XGB) sur les jeux de données de test de 32 institutions. (A) Courbes caractéristiques de l'opérateur du récepteur pour les 32 ensembles de test. (B) Zone sous les valeurs de caractéristique de fonctionnement du récepteur (AUROC) pour les 32 ensembles de test, dans l'ordre décroissant, avec la spécificité correspondante et le rapport de cotes de diagnostic (DOR) à une sensibilité de 0,80.
Commentaire
Les patients atteints d'embolie pulmonaire (EP) qui arrêtent prématurément le traitement anticoagulant (< 90 jours) présentent un risque accru de décès ou de récidive.
Nous avons utilisé les données du registre RIETE pour comparer la capacité pronostique de 5 modèles d'apprentissage automatique (ML) et la régression logistique afin d'identifier les patients présentant un risque accru d'EP fatale ou de thromboembolie veineuse récurrente (TEV) 30 jours après l'arrêt du traitement. . Les modèles ML comprenaient l'arbre de décision, l'algorithme K-Nearest Neighbors, Support Vector Machine, Ensemble et Neural Network [NN]. Un modèle « complet » avec 70 variables et un modèle « réduit » avec 23 ont été analysés. Les performances du modèle ont été évaluées par des métriques de matrice de confusion sur les données de test pour chaque modèle et un tracé de calibrage.
ML-NN était la meilleure méthode d'identification des patients présentant le critère d'évaluation composite, prédisant le résultat composite avec une aire sous la courbe des caractéristiques de fonctionnement du récepteur (ROC) de 0,96 (intervalles de confiance à 95 % [IC], 0,95 à 0,98), en utilisant soit 70 ou 23 variables saisies avant l'arrêt. Des nombres similaires ont été obtenus pour la sensibilité, la spécificité, la valeur prédictive positive, la valeur prédictive négative et l'exactitude. La discrimination de la régression logistique était inférieure (aire sous la courbe ROC, 0,76 [95 % Cl 0,70-0,81]). Le graphique d'étalonnage a montré des écarts similaires par rapport à la ligne parfaite pour ML-NN et la régression logistique.
La méthode ML-NN a très bien prédit le résultat composite après l'arrêt prématuré de l'anticoagulation et a surpassé la régression logistique traditionnelle.
Plusieurs suggestions peuvent être utiles aux cliniciens et aux décideurs qui conçoivent et utilisent des outils d'IA.
https://medvasc.info/1724-ia-mv-2
https://jamanetwork.com/journals/jama/fullarticle/2794258?guestAccessKey=5b716395-ff9c-49a4-8a44-cf89376a0296&utm_source=silverchair&utm_medium=email&utm_campaign=article_alert-jama&utm_content=olf&utm_term=070822
"1/ Les cliniciens ne doivent pas supposer que les paramètres traditionnels, tels que la zone sous la courbe caractéristique de fonctionnement du récepteur, se traduisent par des effets cliniques, car ces paramètres de performance ne sont généralement pas optimisés ou évalués pour des contextes cliniques spécifiques.
2/ Les cliniciens devraient être impliqués dans l'orientation de la conception des métriques pour s'assurer que les algorithmes produisent des résultats cliniquement utiles et centrés sur le patient afin de minimiser les dommages imprévus.
3/ les cliniciens devraient donner la priorité à l'utilisation d'outils d'IA avec des explications bien documentées et compréhensibles des mesures de performance, car cela pourrait permettre de prendre des décisions éclairées sur l'opportunité et la meilleure façon d'utiliser l'algorithme.
4/ les cliniciens doivent s'attendre à une évaluation prospective des algorithmes en milieu clinique. L'évaluation dans divers contextes démontre l'utilité potentielle d'un algorithme pour les résultats cliniques réels.
5/ Les utilisateurs d'outils d'IA devraient exiger que les développeurs d'IA mettent à disposition le code complet d'un algorithme, y compris les données de formation et le code, afin que les métriques utilisées pour développer les algorithmes soient explicites et modifiables.
6/ Les mesures de performance diagnostique doivent tenir compte des performances différentielles dans les sous-groupes de population, en particulier pour les conditions qui peuvent se présenter différemment en fonction de la race, de l'origine ethnique ou du sexe.
Les cliniciens et autres décideurs en matière de soins de santé ont la responsabilité de choisir des algorithmes transparents, cliniquement utiles et efficaces pour diverses populations de patients.
Pour faciliter une décision éclairée, les équipes de développement d'algorithmes doivent également être diversifiées et travailler en étroite collaboration avec les cliniciens pour développer et mettre en œuvre des mesures de performance de l'IA qui intègrent le contexte clinique.
Ce processus devrait également reconnaître et refléter la diversité des objectifs et des parties prenantes en médecine diagnostique afin d'améliorer la pertinence et la représentation des outils d'IA dans la pratique clinique.