"Errare humanum est, perseverare diabolicum" Sénèque (peut être !)
" Igitur quia et errasse humanum est, et confiteri errorem prudentis " ("Puisqu'avoir commis une erreur est humain, et admettre l'erreur est le propre des gens prudents ") Saint Jérôme
https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2823187
Article Libre d'Accès
Les erreurs de diagnostic contribuent de manière substantielle aux préjudices causés aux patients, mais les stratégies de surveillance sont sous-développées.
Les algorithmes de déclenchement électronique (e-triggers) peuvent identifier les patients présentant des erreurs de diagnostic potentielles en utilisant les données du dossier médical électronique (DME). Cependant, leurs valeurs prédictives sont faibles et ce processus nécessite un examen manuel fastidieux des dossiers médicaux pour confirmer les occasions manquées de diagnostic (OMD). Étant donné que les e-triggers sont conçus à l'aide d'hypothèses a priori plutôt que de modèles de données empiriques, ils peuvent ne pas détecter les signaux OMD de manière exhaustive. Nous avons testé si l'apprentissage automatique (ML) peut améliorer les performances des e-triggers et imiter les examinateurs de dossiers médicaux humains à plus grande échelle.
Sur la base des contributions d'experts et des cadres existants, nous avons conçu des déclencheurs électroniques basés sur des règles pour trouver d'éventuels MOD dans les services d'urgence (SU). En utilisant les données nationales du DSE des anciens combattants couvrant plus de 20 millions d'individus uniques, nous avons identifié 2 cohortes à haut risque :
(1) les patients présentant des facteurs de risque d'accident vasculaire cérébral sortis des urgences après avoir présenté des étourdissements ou des vertiges et qui ont ensuite été hospitalisés pour un accident vasculaire cérébral ou un AIT dans les 30 jours
(2) les patients sortis des urgences avec des douleurs abdominales et une température anormale et qui ont ensuite été hospitalisés dans les 10 jours. Toutes les visites aux urgences ont eu lieu entre 2016 et 2020. Des cliniciens formés ont utilisé des instruments de collecte de données standardisés (eFigure 1 dans le supplément 1 ) pour examiner un échantillon aléatoire de dossiers médicaux signalés par chaque déclencheur électronique et étiquetés chacun comme MOD ou sans MOD. Le comité d'examen du Baylor College of Medicine a approuvé l'étude et a accordé une dérogation au consentement éclairé car il ne serait pas possible d'obtenir le consentement pour l'examen des dossiers médicaux du grand nombre de patients que nous avons étudiés. Les analyses ont été menées d'avril 2020 à mai 2024 en utilisant Python version 3.7.4 (Python Software Foundation), avec les packages scipy, numpy et scikit-learn.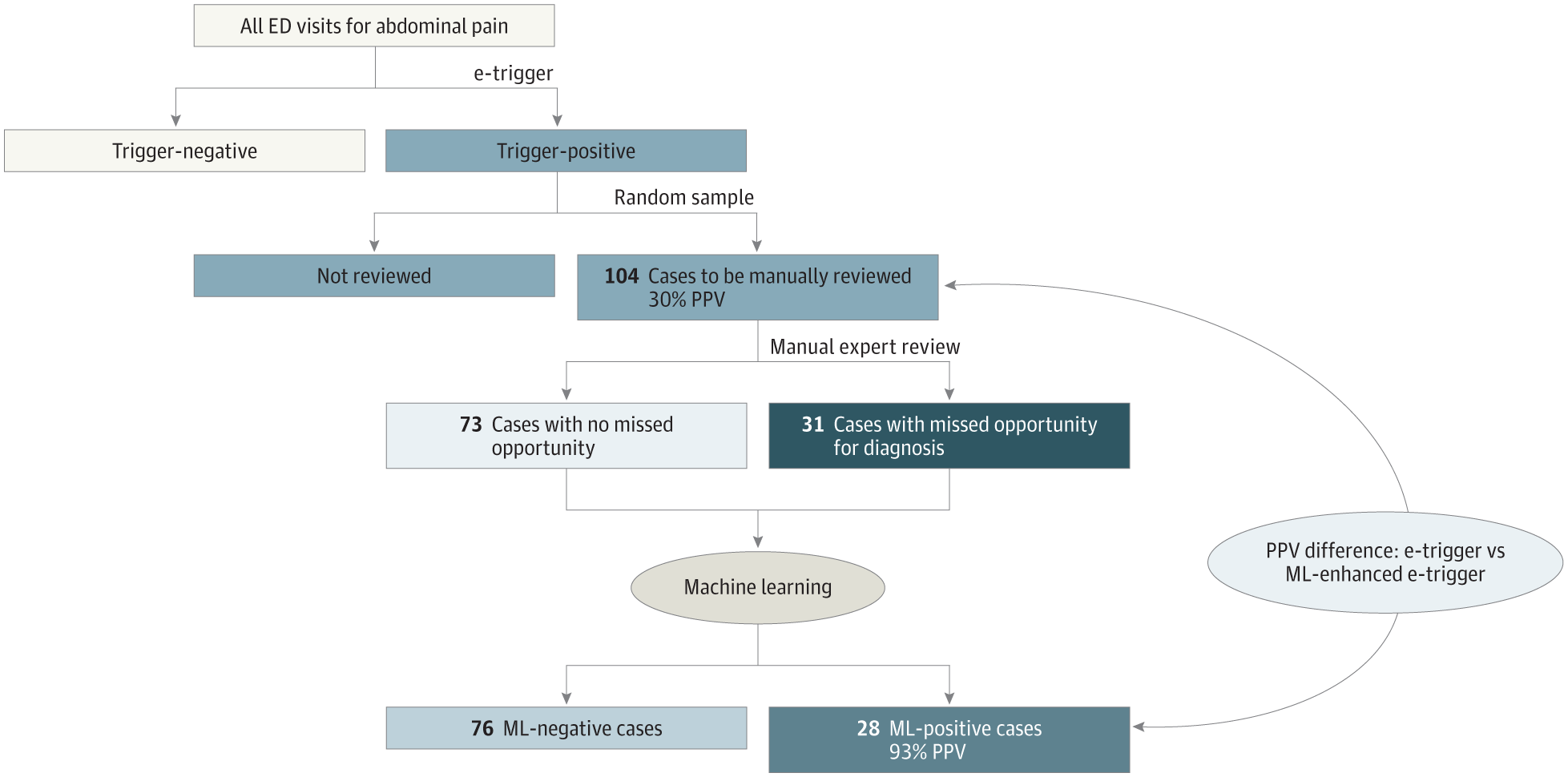
Les dossiers médicaux avec preuve claire de MOD ou pas de MOD ont été divisés en ensembles d'entraînement et de tes. Les méthodes ML étaient la régression logistique régularisée et les forêts aléatoires (avec une profondeur d'arbre maximale limitée pour atténuer le surajustement). Les algorithmes de vertiges et de douleurs abdominales avaient accès à 148 et 153 variables potentiellement associées aux résultats, respectivement, extraites de données structurées du DSE. Il s'agissait notamment de données démographiques, de valeurs de laboratoire, de signes vitaux, d'ordonnances, d'heures de visite et de facteurs de risque (eTableau dans le supplément 1 ). Étant donné que les méthodes imitaient l'évaluation rétrospective de l'examen des dossiers médicaux, plutôt que l'évaluation préhospitalière ou au point de service des urgences, les variables ont été tirées des données indexées des urgences et des données hospitalières ultérieures. Les variables ont été présélectionnées en fonction de l'association bivariée avec le MOD par le test t ou le test χ 2 selon le cas, avec un seuil de signification statistique de P bilatéral = 0,10. Les valeurs prédictives positives (VPP) sont rapportées sous forme de valeurs groupées (ensemble d'entraînement et de test combinés) en raison du nombre limité de dossiers standard de critères étiquetés par les cliniciens. Les IC sont des intervalles de Wald à 95 %.
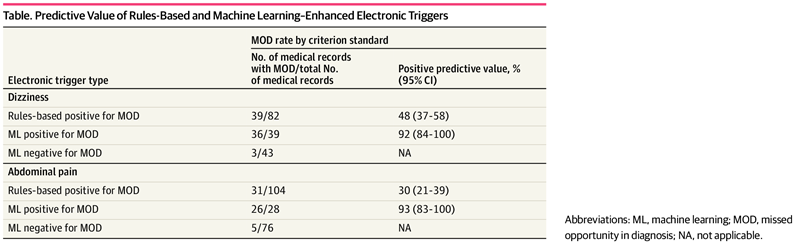
Pour le déclencheur électronique des étourdissements, les évaluateurs ont identifié des MOD dans 39 des 82 dossiers signalés (VPP, 48 % [IC à 95 %, 37 %-58 %]). L'algorithme ML le plus performant (forêt aléatoire) a correctement identifié 36 des 39 vrais MOD et 40 des 43 MOD négatifs (VPP, 92 % [IC à 95 %, 84 %-100 %]). Pour le déclencheur électronique des douleurs abdominales, les évaluateurs ont identifié 31 MOD dans 104 dossiers signalés (VPP, 30 % [IC à 95 %, 21 %-39 %]). Les exemples d'erreurs de diagnostic comprenaient des diagnostics manqués de cholangite, de cholécystite et de colite infectieuse. Le ML a correctement identifié 26 des 31 vrais MOD et 71 des 73 MOD négatifs (VPP, 93 % [IC à 95 %, 83 %-100 %]). Les détails sont présentés dans la figure et le tableau .
L'apprentissage automatique a amélioré la précision des déclencheurs électroniques pour identifier les MOD. Cette amélioration de l'apprentissage automatique pourrait améliorer la capacité d'une organisation à surveiller les erreurs de diagnostic à des fins de recherche, d'apprentissage et d'amélioration de la qualité. De plus, elle réduit considérablement la charge de travail de l'examen manuel des dossiers médicaux par le clinicien. Les limites de cette étude incluent le temps nécessaire pour préparer les variables utilisées par l'apprentissage automatique, bien qu'une fois cette étape terminée, l'algorithme puisse fonctionner à grande échelle. Le petit nombre de dossiers étiquetés par des experts peut limiter la capacité de l'apprentissage automatique à utiliser toutes les données structurées et à estimer les performances des ensembles de tests.
Les prochaines étapes incluent l'intégration du texte des notes cliniques comme source de prédiction des occasions manquées pour exploiter les riches données cliniques nécessaires à la détermination des MOD, l'augmentation du nombre de dossiers étiquetés par des experts sur lesquels l'approche est testée et la validation dans une population externe indépendante. L'apprentissage automatique s'avère prometteur en tant qu'outil permettant d'identifier efficacement les erreurs de diagnostic pour la recherche et l'amélioration de la qualité.
Commentaire
L'IA OUTIL c'est la meilleure manière de se servir de l'IA en médecine. C'est un outil multi tâche, qui va révolutionner nos habitudes mais avec une maîtrise humaine. Identifier les erreurs médicales est une orientation importante, par exemple aux urgences vue le nombre de patients examinés par jour . On entre dans une médecine prédictive de plus en plus précise, l'ignorer serait une grave erreur.
L'IA va t'elle débloquer les attentes aux urgences ?
Question sans réponse à ce jour