"L'intelligence artificielle évoluera pour devenir une superintelligence. Nous devons être attentifs à son développement et veiller à ce qu'il serve les intérêts de l'humanité" Bill Gates, cofondateur de Microsoft
" L'IA nécessitera la collaboration de la créativité humaine et de l'apprentissage automatique pour résoudre certains des défis les plus urgents du monde." Sheryl Sandberg, ancienne directrice des opérations de Facebook
Cao B, Greiner R, Greenshaw A, Sui J. AI and Machine Learning Terminology in Medicine, Psychology, and Social Sciences: Tutorial and Practical Recommendations.
Terminologie de l'IA et de l'apprentissage automatique en médecine, psychologie et sciences sociales : tutoriel et recommandations pratiques
J Med Internet Res. 2025 Aug 18;27:e66100. doi: 10.2196/66100. PMID: 40825233; PMCID: PMC12360722.https://www.jmir.org/2025/1/e66100
Article libre accès
Les applications récentes de l'intelligence artificielle (IA) et de l'apprentissage automatique en médecine, en psychologie et en sciences sociales ont entraîné des confusions terminologiques fréquentes.
Dans cet article, nous examinons les données émergentes issues de revues systématiques documentant une utilisation abusive généralisée de termes clés, notamment le terme « prédiction » appliqué à des études se contentant de démontrer une association ou une analyse rétrospective.
Nous clarifions quand utiliser « prédiction » et recommandons l'utilisation de « prédiction prospective » pour les prédictions futures ; expliquons les procédures de validation essentielles à la généralisabilité des modèles ; abordons le surapprentissage et la généralisation en apprentissage automatique et les méthodes de régression traditionnelles ; clarifions les relations entre les caractéristiques, les variables indépendantes, les prédicteurs, les facteurs de risque et les facteurs causaux ; et clarifions la relation hiérarchique entre l'IA, l'apprentissage automatique, l'apprentissage profond, les grands modèles de langage et l'IA générative. Nous fournissons des recommandations terminologiques fondées sur des données probantes qui peuvent faciliter une communication plus limpide entre les chercheurs de différentes disciplines et entre la communauté scientifique et le public, favorisant ainsi une application rigoureuse de l'IA en médecine, en psychologie et en sciences sociales.
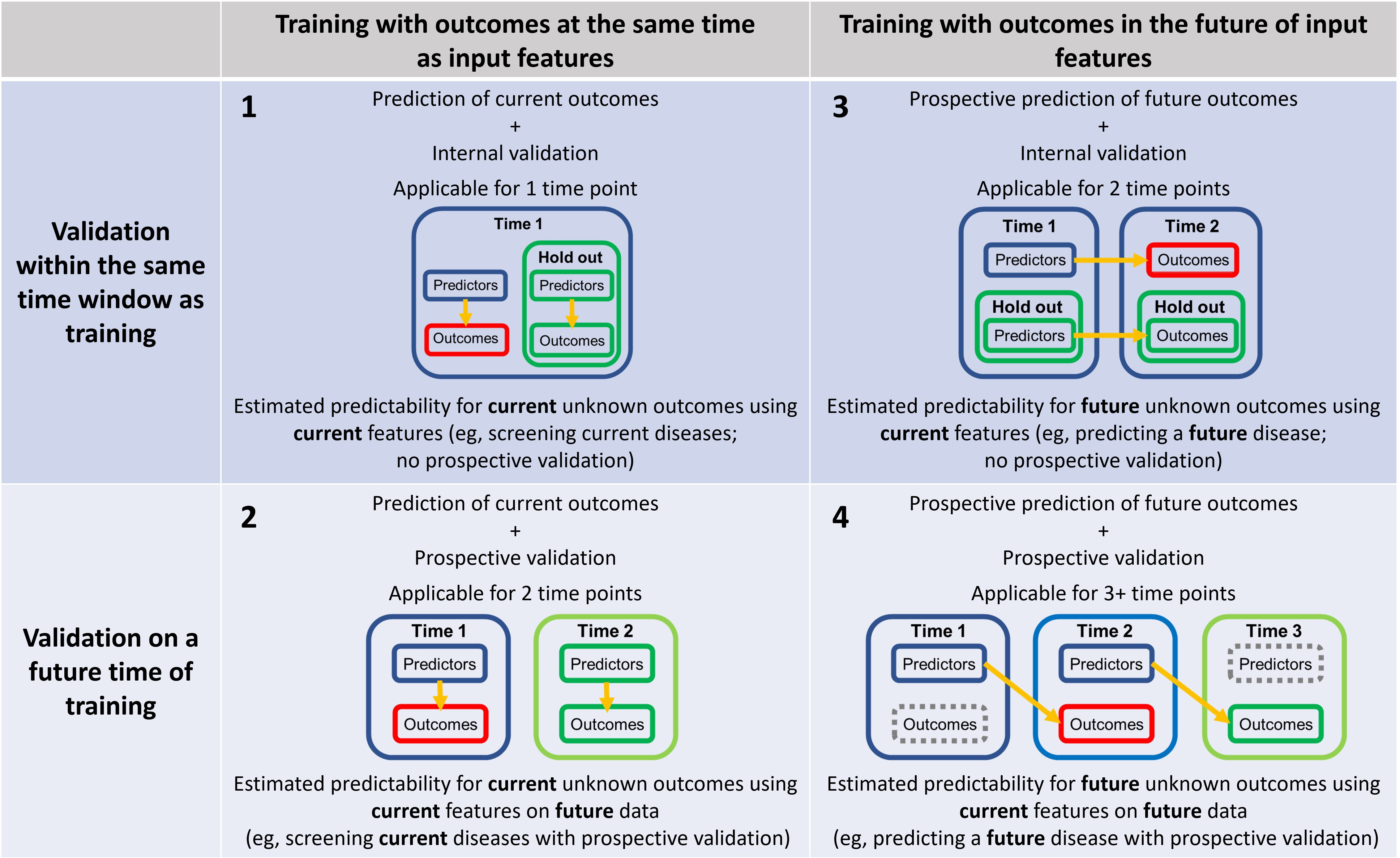
Prédiction des résultats actuels et futurs avec validation actuelle et future.
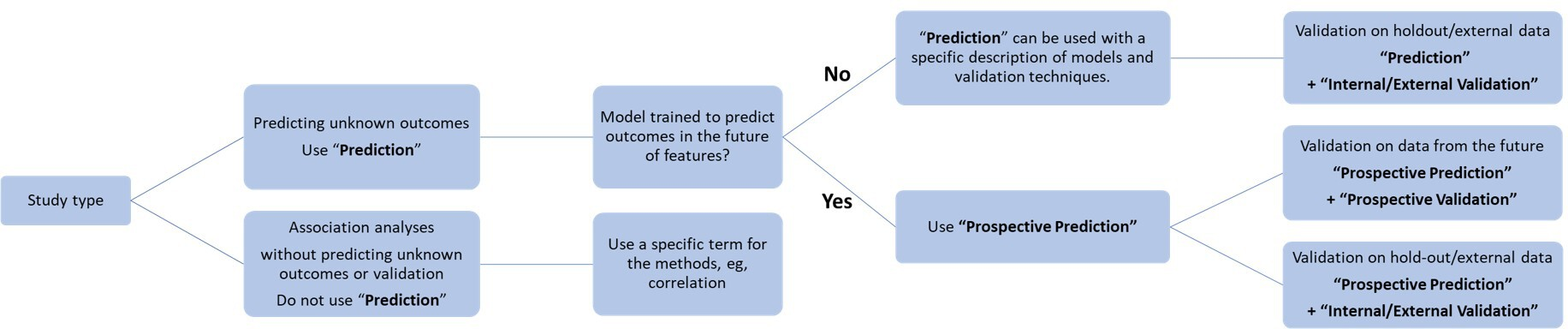
Processus de décision recommandé pour le terme « prédiction » et validations pertinentes.
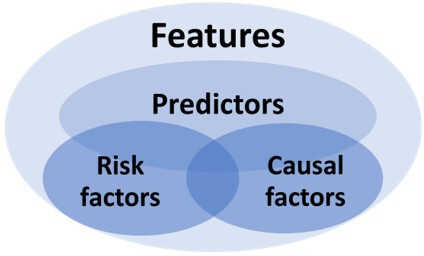
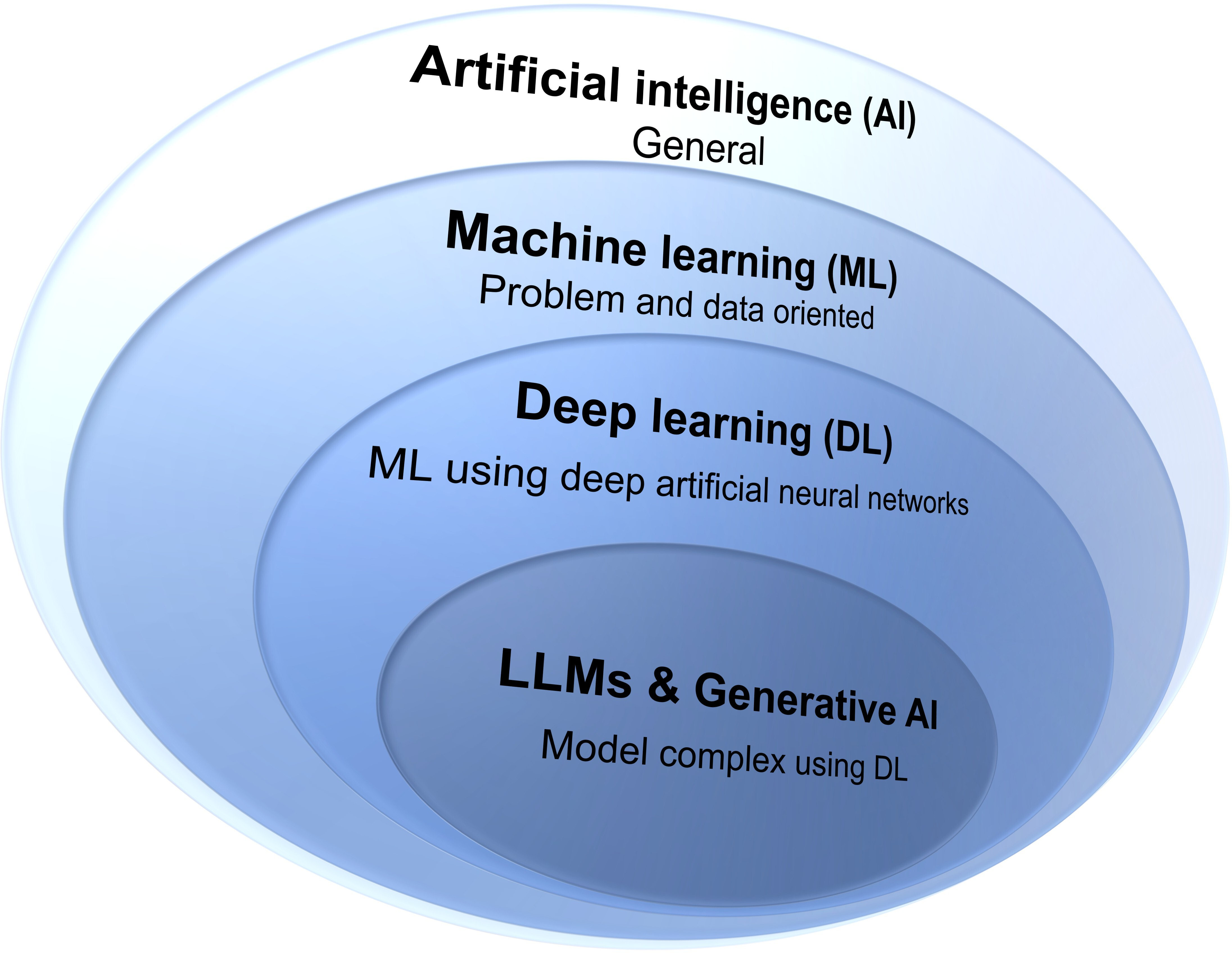
Relations simplifiées entre l'intelligence artificielle (IA), l'apprentissage automatique (AA), l'apprentissage profond (AP), les grands modèles de langage (MLL) et l'intelligence artificielle générative. Les LLM modernes et l'IA générative continuent d'évoluer et d'étendre les capacités de l'AP et de l'AA, surpassant potentiellement l'AA traditionnel.
RESUME GENERATIF
Cet article porte sur la clarification de la terminologie de l'intelligence artificielle et de l'apprentissage automatique dans les domaines de la médecine, de la psychologie et des sciences sociales.
Terminologie de l'intelligence artificielle en Médecine
L'utilisation croissante de l'IA et de l'apprentissage automatique (AA) dans divers domaines a entraîné des confusions terminologiques.
- * La confusion autour du terme "prédiction" est particulièrement répandue, souvent utilisé à tort pour désigner des études d'association.
- * Des études montrent que 61% des études sur le diabète sont des études d'association, tandis que 39% sont des modélisations rétrospectives sans validation externe.
- * La plupart des études en psychologie et en sciences du sport confondent également association et prédiction, avec des taux de 77% et 90% respectivement pour les études d'association.
Défis de la Prédiction dans la recherche
Les défis liés à la terminologie de la prédiction peuvent nuire à la recherche et à la pratique.
- * Les études de McCall et al. montrent que la majorité des études sur la performance sportive analysent des associations plutôt que de faire de vraies prédictions.
- * La mécompréhension des termes comme "validation" et "caractéristiques" complique encore la situation.
- * Les études rétrospectives dominent, avec seulement 7,6% des études en soins de santé primaire étant prospectives.
Recommandations pour l'utilisation de la prédiction
Des recommandations claires sont nécessaires pour l'utilisation appropriée du terme "prédiction".
- * Ne pas utiliser "prédiction" pour des études d'association sans validation.
- * Utiliser "Prédiction Prospective" pour les modèles visant des résultats futurs.
- * Spécifier les méthodes de validation, qu'elles soient internes, externes ou prospectives.
Validation et Test des Modèles
La validation est essentielle pour démontrer la capacité des modèles à prédire des résultats sur de nouvelles données.
- * La validation croisée est une méthode courante pour évaluer les modèles, mais elle doit être correctement mise en œuvre pour éviter le surajustement.
- * Les termes "test" et "validation" sont souvent confondus, mais il est important de préciser les méthodes de validation utilisées.
Surajustement et Méthodes de Régression
Le surajustement est un problème courant dans les modèles d'apprentissage automatique.
- * Les modèles de régression linéaire traditionnels sont particulièrement vulnérables au surajustement, surtout avec un nombre conséquent de caractéristiques.
- * Les modèles de régression régularisés, comme LASSO, aident à prévenir le surajustement en contrôlant les coefficients.
Clarification des termes liés aux variables
Il existe une confusion persistante autour des termes tels que caractéristiques, variables indépendantes et facteurs de risque.
- * Le terme "caractéristique" est prédominant dans la littérature sur l'AA, tandis que "variable indépendante" est plus courant en statistiques traditionnelles.
- * Les variables indépendantes sont conçues pour expliquer ou prédire les variables dépendantes dans les modèles statistiques.
Terminologie des modèles de prédiction en ML
Cette section clarifie l'utilisation des termes liés aux variables dans les modèles de prédiction en apprentissage automatique (ML).
- * Le terme "Feature" est recommandé pour les variables d'entrée dans les modèles ML.
- * "Independent Variables" doit être utilisé dans les contextes de modélisation statistique.
- * "Predictor" est réservé aux variables validées ayant une valeur prédictive.
- * Les "Risk Factors" émergent d'études d'association et nécessitent une analyse supplémentaire pour confirmer leur contribution.
- * Les "causal factors" nécessitent des conceptions expérimentales contrôlées pour établir des relations causales.
- * Les "features" englobent tous les prédicteurs potentiels, facteurs de risque et facteurs causaux.
AI, ML, DL et LLMs
Cette section aborde les distinctions entre l'intelligence artificielle (AI), l'apprentissage automatique (ML), l'apprentissage profond (DL) et les modèles de langage de grande taille (LLMs).
- * AI est un terme général englobant tout algorithme qui imite l'intelligence humaine.
- * ML est un sous-ensemble d'AI qui apprend des modèles à partir des données.
- * DL est une forme spécialisée de ML utilisant des réseaux de neurones multicouches.
- * Les LLMs sont des réseaux de neurones profonds avec des milliards de paramètres, principalement utilisés pour prédire le terme suivant dans un contexte donné.
- * La popularité croissante de DL soulève des préoccupations concernant l'interprétabilité des modèles complexes.
Recommandations pour l'utilisation des termes
Cette section fournit des recommandations sur l'utilisation appropriée des termes AI, ML, DL et LLMs dans la recherche.
- * Utiliser le terme le plus spécifique possible pour décrire les applications de recherche.
- * Les études utilisant des LLMs ou des modèles génératifs doivent être étiquetées comme telles, plutôt que comme "ML".
- * La spécificité dans l'application des modèles génératifs est essentielle pour éviter la confusion sur leurs capacités et objectifs.
Conclusions et implications
Cette section résume les clarifications terminologiques et les recommandations pour l'application de l'AI et du ML.
- * La terminologie précise est cruciale pour la communication entre chercheurs et cliniciens.
- * Les recommandations visent à améliorer la qualité de la recherche et les résultats en santé et en sciences sociales.
- * L'évolution rapide des technologies AI nécessite une attention continue à la précision terminologique.
SYNTHÈSE
Cet article est un tutoriel et un ensemble de recommandations pratiques visant à clarifier la terminologie souvent confuse entourant l'intelligence artificielle (IA) et l'apprentissage automatique (ML) dans les domaines de la médecine, de la psychologie et des sciences sociales. La principale confusion provient de l'usage inapproprié du terme «prédiction» pour décrire des études qui démontrent en réalité une simple association ou une analyse rétrospective, sans validation sur de nouvelles données. Les auteurs définissent quand la «prédiction prospective» doit être utilisée pour les résultats futurs, insistent sur l'importance de la validation pour assurer la généralisabilité du modèle et discutent du surapprentissage (overfitting). Enfin, le document établit une clarification hiérarchique entre les termes IA, ML, apprentissage profond (DL), modèles de langage volumineux (LLM) et IA générative, tout en recommandant l'utilisation d'une terminologie précise et spécifique pour améliorer la communication scientifique. NoteBookKLM
À LIRE
VOCABULAIRE l'IA
https://www.enseignementsup-recherche.gouv.fr/fr/bo/19/Hebdo6/CTNR1832601K.htm
L’intelligence artificielle : un domaine en constante évolution
Machine learning, big data, chatbot : derrière ces anglicismes indissociables du domaine de l’intelligence artificielle se cachent des concepts, méthodes ou systèmes qui semblent obscurs. Pourtant, leurs applications sont multiples, font l’actualité depuis plusieurs mois et sont scrutées par les instances. Vous avez déjà entendu parler d’unsupervised learning, d’IA générative ou de prompt, mais vous avez du mal à à comprendre ce qui ce cache concrètement derrière ces expressions ? Pas de panique : dans cet article, nous expliquons, le plus simplement et succinctement possible, la signification des termes les plus couramment utilisés.
15 termes indissociables de l’intelligence artificielle
- Algorithme : désigne prosaïquement « une suite d’étapes permettant d’obtenir un résultat à partir des éléments fournis en entrée » selon la CNIL, qui compare le principe à une recette de cuisine. Dans le domaine de l’intelligence artificielle, l’algorithme s’appuie sur des modèles mathématiques complexes. Il n’est pas déterministe mais « auto-apprenant » : le traitement et l’analyse d’une immense quantité de données lui permettent de s’adapter, d’évoluer et de se reconfigurer pour fournir des résultats précis.
- Machine learning : correspond à un champ d’étude de l’intelligence artificielle appelé « apprentissage automatique » en français. Concrètement, le machine learning regroupe plusieurs méthodologies dont la finalité est d’enseigner l’autonomie à un programme informatique. Après une phase d’entraînement préliminaire sur un large corpus de données, le programme est capable de résoudre des problèmes pour lesquels il n’a pas été développé.
- Supervised learning : relatif à un procédé de machine learning baptisé « apprentissage supervisé » en français. Le principe : entraîner un programme à prédire un résultat en fonction d’occurrences constatées sur une base d’exemples. L’apprentissage supervisé est principalement utilisée pour classifier et détecter des anomalies ou établir des probabilités dans un contexte donné. Exemple : la détection de spams.
- Unsupervised learning : aussi appelée « apprentissage non-supervisé » en français, cette méthode d’apprentissage automatique doit, comme son nom l’indique, permettre à un programme de produire un résultat sans supervision à partir de données brutes. Selon la CNIL, le principe s’articule autour de « la détection de similarités » entre les données étudiées. L’apprentissage non-supervisé peut être, par exemple, utilisé par les algorithmes de recommandations, à même de prédire un comportement ou besoin en fonction des habitudes de navigation.
- Reinforcement learning : ou « apprentissage par renforcement » en français, ce procédé de machine learning est comparé à du dressage car il s’articule autour d’un système de récompenses. En bref, l’apprentissage par renforcement apprend à un programme à fonctionner en autonomie, en le confrontant à des situations dont il tire des leçons. « Au fil des expériences, le système cherche un comportement décisionnel optimal, en ce sens qu’il maximise la somme des récompenses au cours du temps » complète la CNIL.
- Réseaux de neurones artificiels : exploités par les voitures autonomes ou les assistants virtuels, les réseaux de neurones artificiels s’inspirent de la structure du cerveau humain. Pour faire simple, le modèle se divise en plusieurs couches de neurones « auto-apprenants » qui ont préalablement ingéré de l’information. Assemblés en réseaux, les neurones se multiplient et interagissent pour réaliser une tâche ou résoudre un problème.
- IA générative : désigne un système capable de générer du texte, des images ou d’autres types de contenus (audio, vidéo, etc.) à l’aide d’une requête textuelle. Plutôt que de classer ou prédire, les IA génératives produisent du contenu en s’appuyant sur un modèle de langage (voir plus bas) entraîné sur une large base de données.
- Chatbot : aussi appelé « agent conversationnel » en français, le chatbot est un programme capable de mener une conversation avec un utilisateur en mimant le comportement humain. Il peut répondre à des requêtes en fonction de scénarios prédéfinis ou en autonomie grâce à l’apprentissage automatique.
- Big Data : traduit le phénomène de massification des données numériques avec le développement des nouvelles technologies, ainsi que le domaine dédié au traitement de ces « mégadonnées » par le biais d’algorithmes.
- IA faible : correspond au périmètre de l’intelligence artificielle tel qu’on le connaît, selon l’UNESCO. En résumé, une IA faible est capable d’exécuter une (ou plusieurs) tâches de façon autonome, mais dans un cadre défini par l’homme. Elle n’a pas de conscience ou de sensibilité à l’inverse de l’IA forte : un concept qui relève de la fiction à ce jour, rappelle l’organisme.
- Prompt : traduction littérale de « réplique » en français, le terme désigne les requêtes textuelles adressées par les utilisateurs à des systèmes d’IA génératives tels que ChatGPT, DALL-E ou Midjourney. En fonction de l’affinage et de la contextualisation du prompt, la réponse apportée sera plus ou moins exhaustive.
- Transformer : correspond à un réseau de neurones artificiels développé initialement pour le traitement automatique du langage, notamment pour la traduction ou la génération de textes. Les Transformers peuvent « réaliser l’essentiel, voire tout leur apprentissage de manière non supervisée, c’est-à-dire sur des textes « bruts » sans plus d’information ou d’annotation sur leur contenu » selon Michel Poujol, expert de l’IA interrogé par BDM.
- Modèle de langage : désigne un programme capable de comprendre et imiter le langage humain après une analyse complète de la structure d’une langue, ses règles implicites ou explicites et ses nuances.
- GPT-4 : acronyme de Generative Pre-trained Transformer 4, modèle de langage multimodal développé par la société américaine OpenAI pour, notamment, alimenter son agent conversationnel ChatGPT.
- PaLM-2 : acronyme de Pathways Language Model-2, modèle de langage développé par Google et entraîné sur plusieurs milliards de paramètres. Il est destiné à alimenter Google Bard, le générateur de texte lancé par la firme en février 2023.
https://www.blogdumoderateur.com/lexique-intelligence-artificielle/
Copyright : Dr Jean-Pierre Laroche / 2025