« L’intelligence de la machine est la dernière invention que l’humanité aura besoin de faire. » Nick Bostrom
« Le défi majeur de l’intelligence artificielle est de parvenir à aligner les objectifs des systèmes intelligents avec les valeurs et les préférences de l’humanité, afin d’assurer leur utilité et leur sécurité à long terme. » Stuart J. Russell,
Dayan R, Uliel B, Koplewitz G. Age against the machine—suscep tibility of large language models to cognitive impairment: cross sectional analysis
L 'âge face à la machine : la vulnérabilité des grands modèles linguistiques aux troubles cognitifs : analyse transversale
https://www.bmj.com/content/387/bmj-2024-081948
Données préliminaires
L 'Évaluation Cognitive de Montréal (MoCA)
Quel est l’objet d’évaluation du MoCA?
Le MoCA est un outil de dépistage de l’atteinte neurocognitive et il est dédié principalement au dépistage de l’atteinte plus légère.
En quoi consiste le MoCA?
Le MoCA est un questionnaire à réponses courtes incluant quelques tâches que doit accomplir la personne. Les éléments évalués sont regroupés en six sous-sections : mémoire à court terme, habiletés visuospatiales, fonctions exécutives, attention, concentration, mémoire de travail, langage et orientation dans le temps et l’espace. Les épreuves qui y sont proposées sont souvent plus complexes que celles retrouvées dans le MMS
https://cnfs.ca/agees/tests/mesurer-l-etat-cognitif/montreal-cognitive-assessment-moca
Les tâches visuospatiales/exécutives
Quel est le rôle des fonctions visuo-spatiales? Les fonctions visuo-spatiales permettent de distinguer un objet selon les orientations de ses lignes, de l'examiner sous tous ses angles. Elles permettent de positionner cet objet dans l'espace (par rapport à soi et par rapport à notre environnement).
L'ARTICLE du BMJ
Objectif
Évaluer les capacités cognitives des principaux grands modèles linguistiques et identifier leur susceptibilité aux troubles cognitifs, en utilisant l'Évaluation Cognitive de Montréal (MoCA) et des tests supplémentaires.
Conception
Analyse transversale.
Configuration de l'interaction en ligne avec de grands modèles linguistiques via des invites textuelles.
Participants
Modèles de langage volumineux accessibles au public, ou « chatbots » : ChatGPT versions 4 et 4o (développés par OpenAI), Claude 3.5 « Sonnet » (développé par Anthropic) et Gemini versions 1 et 1.5 (développées par Alphabet).
Le test MoCA (version 8.1) a été administré aux principaux grands modèles de langage avec des instructions identiques à celles données aux patients humains. La notation a suivi les directives officielles et a été évaluée par un neurologue en exercice. Des évaluations supplémentaires comprenaient la figure de Navon, l'image du vol de biscuits, la figure de Poppelreuter et le test de Stroop.
Principaux résultats mesurés
Scores MoCA, performances dans les tâches visuospatiales/exécutives et résultats du test Stroop.
Résultats
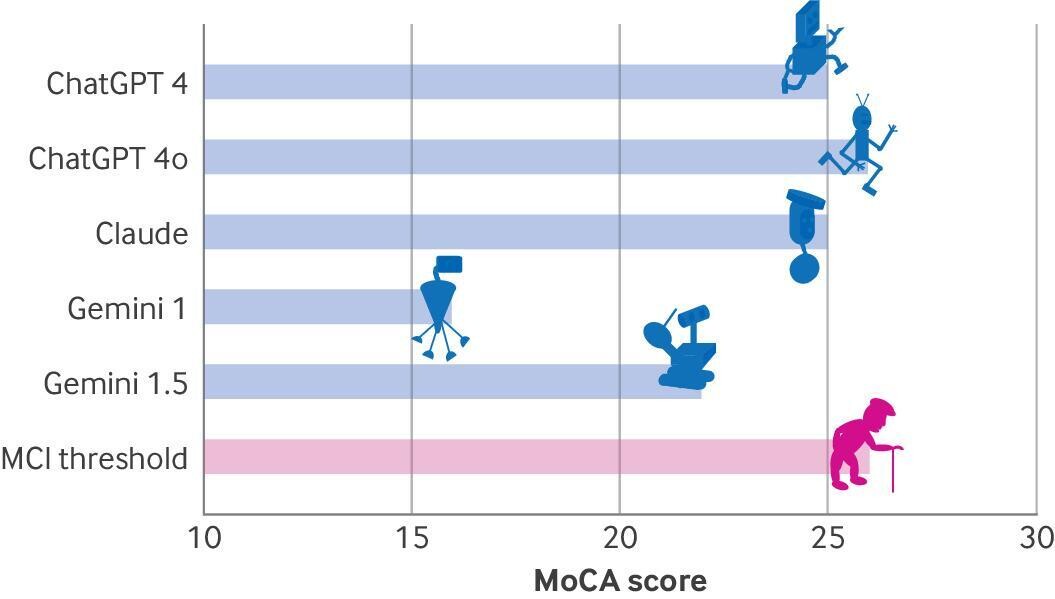
Score de l'Évaluation cognitive de Montréal (MoCA) (sur 30) de différents grands modèles de langage. MCI = déficience cognitive légère
Performance à la section visuospatiale/exécutive du test d'évaluation cognitive de Montréal (MoCA). A : tâche de création de sentiers B (TMBT) du test MoCA. B : solution TMBT correcte, complétée par un participant humain. C : solution TMBT incorrecte, complétée par Claude. D et E : solutions TMBT incorrectes (bien que visuellement attrayantes), complétées par les versions 4 et 4o de ChatGPT, respectivement. F : cube Necker que le participant est invité à copier. G : solution correcte à la tâche de copie de cube, dessinée par un participant humain. H : solution incorrecte à la tâche de copie de cube, lignes « arrière » manquantes, complétée par Claude. I et J : solutions incorrectes à la tâche de copie de cube par les versions 4 et 4o de ChatGPT. Les ombres et les traits de crayon artistiques sont notables, même si les deux modèles n'ont pas réussi à copier le cube avec précision comme demandé (la version 4o a finalement réussi cette tâche lorsqu'on lui a demandé de dessiner en utilisant l'art ascii).
ChatGPT 4o a obtenu le score le plus élevé au test MoCA (26/30), suivi de ChatGPT 4 et Claude (25/30), Gemini 1.0 ayant obtenu le score le plus bas (16/30). Tous les grands modèles de langage ont montré de faibles performances dans les tâches visuospatiales/exécutives. Les modèles Gemini ont échoué à la tâche de rappel différé. Seul ChatGPT 4o a réussi l'étape incongruente du test Stroop.
Conclusions
l’exception de ChatGPT 4o, presque tous les grands modèles linguistiques soumis au test MoCA ont montré des signes de déficience cognitive légère. De plus, comme chez les humains, l’âge est un déterminant clé du déclin cognitif : les chatbots « plus âgés », comme les patients plus âgés, ont tendance à avoir de moins bons résultats au test MoCA. Ces résultats remettent en cause l’hypothèse selon laquelle l’intelligence artificielle remplacera bientôt les médecins humains, car la déficience cognitive évidente chez les principaux chatbots peut affecter leur fiabilité dans les diagnostics médicaux et miner la confiance des patients.
" Cette étude représente une exploration novatrice des capacités cognitives des grands modèles linguistiques à l’aide de l’Évaluation cognitive de Montréal et d’autres outils de diagnostic. Nos résultats indiquent que même si les grands modèles linguistiques affichent une compétence remarquable dans plusieurs domaines cognitifs, ils présentent des déficits notables dans les fonctions visuospatiales et exécutives, comparables à une déficience cognitive légère chez les humains. Aucun des grands modèles linguistiques n’a « réussi » le test MoCA, selon le jargon d’un président américain .
L’échec uniforme de tous les grands modèles de langage dans les tâches nécessitant une abstraction visuelle et une fonction exécutive met en évidence un domaine de faiblesse important qui pourrait entraver leur utilité dans les contextes cliniques.
Réponse by PERPLEXITY IA
- La plupart des chatbots ont échoué aux tests visuospatiaux
- Ils n'ont pas pu faire preuve d'empathie ou interpréter avec précision des scènes visuelles complexes
- Seul ChatGPT 4o a réussi l'étape incongruente du test Stroop, qui mesure l'interférence cognitive
L'échec uniforme des LLM dans les tâches nécessitant une abstraction visuelle et une fonction exécutive révèle une faiblesse importante
Cette limitation pourrait effectivement entraver leur utilisation dans des contextes cliniques, en particulier pour :
* L'évaluation des fonctions exécutives, qui incluent la planification, la capacité d'abstraction, le contrôle attentionnel, l'inhibition, la flexibilité cognitive et la mémoire de travail
- * L'interprétation de tests visuospatiaux, cruciaux pour le diagnostic de certains troubles cognitifs.
Implications plus larges
*Cette étude remet en question l'idée que l'IA pourrait rapidement remplacer les médecins humains, en particulier dans des domaines comme la neurologie*Elle souligne l'importance des compétences humaines dans l'interprétation de tâches complexes et l'évaluation des fonctions cognitives.
*Il est important de noter que ces résultats sont observationnels et que des différences fondamentales existent entre le cerveau humain et les modèles de langage
Néanmoins, ces découvertes mettent en lumière des domaines où l'amélioration des modèles d'IA est nécessaire avant leur intégration complète dans la pratique clinique."
L’incapacité des grands modèles de langage à faire preuve d’empathie et à interpréter avec précision des scènes visuelles complexes souligne encore davantage leurs limites pour remplacer les médecins humains. Non seulement les neurologues ne sont pas susceptibles d’être remplacés par de grands modèles de langage dans un avenir proche, mais nos résultats suggèrent qu’ils pourraient bientôt se retrouver à traiter de nouveaux patients virtuels – des modèles d’intelligence artificielle présentant des troubles cognitifs."
https://libguides.biblio.usherbrooke.ca/IA/notions
Ce que l'on sait déjà sur ce sujet
-
Les progrès colossaux dans le domaine de l’intelligence artificielle ont donné lieu à une vague de spéculations enthousiastes et effrayantes quant à savoir si les chatbots surpassent les médecins humains.
-
De nombreuses études ont montré que les grands modèles de langage (LLM) sont remarquablement compétents dans une gamme de tâches de diagnostic médical, surpassant les médecins humains
-
Si nous devons nous fier aux LLM pour le diagnostic et les soins médicaux, nous devons examiner leur sensibilité aux déficiences humaines telles que le déclin cognitif.
Ce que cette étude ajoute
-
Presque tous les LLM de premier plan (« ChatGPT », « Claude », « Gemini ») ont montré des signes de déficience cognitive légère au test d’évaluation cognitive de Montréal, en particulier dans la sphère visuospatiale
-
Comme chez les humains, l’âge est un facteur déterminant du déclin cognitif, les versions « plus anciennes » des chatbots, comme les patients plus âgés, ayant tendance à obtenir de moins bons résultats au test.
-
Ces résultats remettent en cause l’hypothèse selon laquelle l’intelligence artificielle remplacera bientôt les médecins humains
Commentaire
Pourquoi les grands modèles de langage ne peuvent auto entretenir leurs connaissances , se perfectionner régulièrement ?
Les troubles cognitifs chez l'humain sont souvent très difficiles à diagnostiquer, l'IA est en difficulté là où le médecin peut être plus précis et apporter un diagnostic plus fiable en le complétant par la biologie et le TEP SCAN !
- « Les machines seront peut-être capables un jour de penser, mais elles seront toujours incapables de rêver. » Walter Lippmann
- « Tout l’effort de l’intelligence artificielle consiste essentiellement à lutter contre la rigidité des ordinateurs. » Douglas Hofstadter,
A LIRE