«L’intelligence artificielle doit rester un outil au service du médecin sans décider à sa place» Luc Lenoir
" Nous sommes en passe d'inventer les machines qui nous soigneront mieux que nous sommes capables de nous soigner nous-mêmes. L'intelligence artificielle se dressera bientôt contre la maladie, avec une implacable efficacité. " Jean Emmanuel Bidault.....Pas contre les médecins !
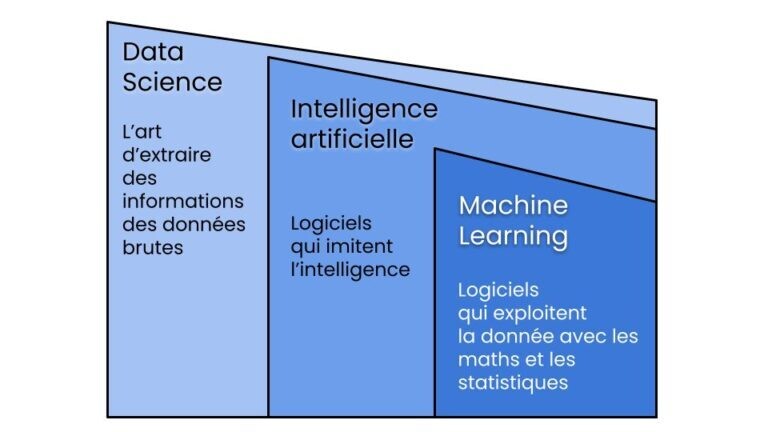
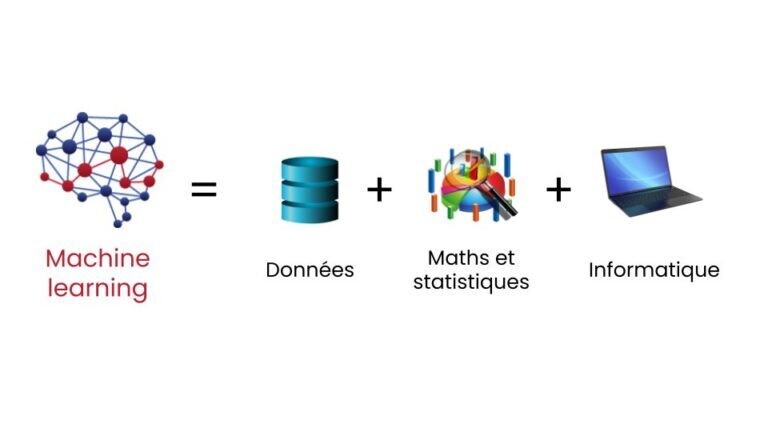
Le Machine Learning ou apprentissage automatique est un domaine scientifique, et plus particulièrement une sous-catégorie de l’intelligence artificielle. Elle consiste à laisser des algorithmes découvrir des « patterns », à savoir des motifs récurrents, dans les ensembles de données. Ces données peuvent être des chiffres, des mots, des images, des statistiques…
Tout ce qui peut être stocké numériquement peut servir de données pour le Machine Learning. En décelant les patterns dans ces données, les algorithmes apprennent et améliorent leurs performances dans l’exécution d’une tâche spécifique.
Pour résumer, les algorithmes de Machine Learning apprennent de manière autonome à effectuer une tâche ou à réaliser des prédictions à partir de données et améliorent leurs performances au fil du temps. Une fois entraîné, l’algorithme pourra retrouver les patterns dans de nouvelles données.
Comment fonctionne le Machine Learning ?
Le développement d’un modèle de Machine Learning repose sur quatre étapes principales. En règle générale, c’est un Data Scientist qui gère et supervise ce procédé.
La première étape consiste à sélectionner et à préparer un ensemble de données d’entraînement. Ces données seront utilisées pour nourrir le modèle de Machine Learning pour apprendre à résoudre le problème pour lequel il est conçu.
Les données peuvent être étiquetées, afin d’indiquer au modèle les caractéristiques qu’il devra identifier. Elles peuvent aussi être non étiquetées, et le modèle devra repérer et extraire les caractéristiques récurrentes de lui-même.
Dans les deux cas, les données doivent être soigneusement préparées, organisées et nettoyées. Dans le cas contraire, l’entraînement du modèle de Machine Learning risque d’être biaisé. Les résultats de ses futures prédictions seront directement impactés.
La deuxième étape consiste à sélectionner un algorithme à exécuter sur l’ensemble de données d’entraînement. Le type d’algorithme à utiliser dépend du type et du volume de données d’entraînement et du type de problème à résoudre.
La troisième étape est l’entraînement de l’algorithme. Il s’agit d’un processus itératif. Des variables sont exécutées à travers l’algorithme, et les résultats sont comparés avec ceux qu’il aurait du produire. Les » poids » et le biais peuvent ensuite être ajustés pour accroître la précision du résultat.
On exécute ensuite de nouveau les variables jusqu’à ce que l’algorithme produise le résultat correct la plupart du temps. L’algorithme, ainsi entraîné, est le modèle de Machine Learning.
La quatrième et dernière étape est l’utilisation et l’amélioration du modèle. On utilise le modèle sur de nouvelles données, dont la provenance dépend du problème à résoudre.Par exemple, un modèle de Machine Learning conçu pour détecter les spams sera utilisé sur des emails.
https://mlab.ai/non-classe/quest-ce-que-machine-learning/
https://fr.wikipedia.org/wiki/Apprentissage_automatique

Auerbach AD. Jeter les bases de l'utilisation de l'intelligence artificielle dans le diagnostic. JAMA Netw Open. 2024;7(9):e2431907. doi:10.1001/jamanetworkopen.2024.31907
Article libre d'accès
L’étude de Zimolzlak et al. 1 dans ce numéro de JAMA Network Open fait partie de ce qui sera bientôt un flot de recherches qui se concentrent sur le rôle de l’intelligence artificielle (IA) dans l’identification des problèmes de processus de diagnostic et des erreurs de diagnostic (également appelées opportunités de diagnostic), avec l’objectif global de catalyser l’amélioration du diagnostic.
À la base, la recherche sur les processus et les résultats de diagnostic est un domaine de mesure : mesure de la rapidité, de l’exactitude, de l’équité et de l’efficacité.
Dans le cas du diagnostic, cela peut parfois être très simple, comme dans le cas de résultats inattendus au moment de l’autopsie.
Dans d’autres cas, les erreurs de diagnostic sont au cœur d’une pratique clinique, mais la frontière entre les défauts de diagnostic et les problèmes étroitement liés, comme le surtraitement, est moins claire.
Les méthodes peuvent être entièrement pilotées par des données administratives avec des défis en termes de validité apparente, ou des méthodes manuelles qui sont précises mais très chronophages et difficiles à diffuser.
Enfin, une certaine combinaison de données de diagnostic et d’événements peut être utilisée pour identifier les cas où des problèmes de diagnostic ont pu se produire, une approche appelée déclencheurs électroniques (e-triggers) .
Par conséquent, nous disposons de peu de moyens évolutifs, efficaces et précis pour identifier où une erreur s’est produite et, par conséquent, pour soutenir les efforts visant à réduire ces mêmes erreurs.
L’IA, grâce à sa capacité à traiter des données complexes et interdépendantes, est très prometteuse dans le domaine de l’amélioration du diagnostic.
L’IA et l’apprentissage automatique pour les modèles prédictifs utilisent des données de grande dimension pour identifier les patients ou les cas où un événement – dans ce cas, une erreur de diagnostic – est le plus probable.
Pour le domaine de l’amélioration du diagnostic, cette approche est très prometteuse comme moyen de détecter les cas où une opportunité de diagnostic existe, ce qui peut à son tour aider à résoudre les problèmes de précision et d’évolutivité mentionnés précédemment.
Il est particulièrement nécessaire de disposer de méthodes offrant une sensibilité et une spécificité suffisamment élevées pour une erreur afin d’éviter (ou du moins de réduire considérablement) les examens manuels des dossiers médicaux.
L'étude de Zimzolak et al 1 vise à relever ce défi en utilisant des méthodes d'IA établies pour améliorer les performances des déclencheurs électroniques.
Les déclencheurs spécifiques basés sur des règles qu'ils ont utilisés visaient à identifier :
(1) les patients présentant des facteurs de risque d'accident vasculaire cérébral sortis du service des urgences (SU) après avoir présenté des étourdissements ou des vertiges et qui ont ensuite été hospitalisés pour un accident vasculaire cérébral ou un accident ischémique transitoire dans les 30 jours
(2) les patients sortis des urgences avec des douleurs abdominales et une température anormale et qui ont ensuite été hospitalisés dans les 10 jours. Les cliniciens ont examiné un échantillon aléatoire de dossiers médicaux signalés par chaque déclencheur électronique et ont étiqueté chacun comme impliquant une opportunité manquée de diagnostic (OMD) ou non. Enfin, les dossiers médicaux présentant des preuves claires d'OMD ou d'absence d'OMD ont été divisés en ensembles d'entraînement et de test d'apprentissage automatique.
L’algorithme d’apprentissage automatique le plus performant a obtenu une valeur prédictive positive pour les MOD dans la cohorte d’AVC de 92 % et de 93 % parmi les patients souffrant de douleurs abdominales et de fièvre, ce qui suggère que l’utilisation de modèles de données plus complexes peut effectivement surpasser les algorithmes plus simples utilisés dans les déclencheurs électroniques, en termes statistiques. Les valeurs prédictives positives élevées de leurs méthodes encadrent à leur tour une approche qui pourrait aider les systèmes de santé à concentrer leurs efforts sur les cas où il est très probable qu’une erreur de diagnostic ait eu lieu.
Cette méthode n’aborde pas directement les questions qui découlent de l’identification des cas, comme les maladies ou les scénarios cliniques les plus associés aux erreurs et les plus faciles à traiter, ou les facteurs liés au médecin ou à l’équipe qui conduisent aux erreurs. Elle aborde également des questions liées aux systèmes de soins, aux dossiers médicaux électroniques et aux défis liés à la charge de travail et à la main-d’œuvre. Il semble probable que cette compréhension nécessitera l’inspection des dossiers médicaux ou une analyse plus approfondie des données électroniques, à la fois pour recueillir les données requises et pour élaborer les récits et les points d’enseignement qui encadrent les interventions. Cela ne signifie pas que l’amélioration de la capacité à identifier les cas n’est pas une avancée louable, mais plutôt qu’elle permet de cibler l’amélioration de la qualité de manière plus étroite et plus approfondie.
Il convient de noter quelques réserves concernant les méthodes utilisées. Tout d’abord, les auteurs ont utilisé une liste assez longue de variables qui ont produit des résultats solides dans leur contexte, mais qui peuvent poser des problèmes importants ailleurs. Les données sont susceptibles d’être collectées différemment ou d’avoir des significations différentes dans des systèmes de santé dotés de modèles de données différents ou, plus fondamentalement, de flux de travail ou d’outils différents dans lesquels les données sont collectées. Ensuite, l’impact de ces méthodes en termes d’équité en santé mérite d’être examiné ultérieurement, car le rôle des biais dans la production d’erreurs de diagnostic semble de plus en plus probable. Et enfin, il reste à voir comment ce modèle fonctionne au fil du temps. La dégradation des performances du modèle est relativement peu étudiée et a des implications à la fois cliniques et opérationnelles, car l’entretien et la maintenance des modèles d’IA peuvent devenir substantiels à mesure que le nombre de modèles augmente.
Il est également important de souligner que la méthode utilisée dans cette étude par Zimzolak et al.1, bien qu’il s’agisse d’un type d’IA, est différente de l’approche du modèle de langage à grande échelle (LLM).
Les LLM suscitent un vif intérêt en tant que solution potentielle à une série de problèmes de diagnostic clinique, de la possibilité de suggérer un diagnostic différentiel à l’identification des erreurs de diagnostic. L’application des LLM est particulièrement convaincante car elle utilise une plus grande étendue d’informations que celle qu’un clinicien pourrait raisonnablement examiner et, dans cette optique, surmonte les problèmes clés de la charge cognitive qui sont au cœur des biais et des aspects du traitement de la pensée des erreurs de diagnostic. En outre, les LLM peuvent créer une aide à la décision clinique qui tient davantage du dialogue que de l’alerte. Dans ces scénarios, la mesure et la précision ne sont pas ignorées mais souvent laissées au clinicien qui reçoit les résultats pour qu’il en juge par lui-même. Les LLM sont au début de leur développement et de leur déploiement en matière d’excellence diagnostique et constituent la prochaine étape de l’IA, à la fois dans le contexte dans lequel l’étude de Zimzolak et ses collègues 1 est destinée – identifier les cas pour une évaluation plus approfondie – ainsi que pour éventuellement fournir une véritable assistance clinique au point de service.
Les modèles d’IA et d’apprentissage automatique sont déjà présents et vont rapidement se développer en termes d’omniprésence dans les soins de santé. Ils reposent sur des travaux visant à définir la précision et la fiabilité de l’IA en tant qu’outil de mesure. À partir de là, nous pouvons élaborer les interventions et les programmes qui amélioreront les soins.
"Les erreurs de diagnostic contribuent de manière substantielle aux préjudices causés aux patients, mais les stratégies de surveillance sont sous-développées. Les algorithmes de déclenchement électronique (e-triggers) peuvent identifier les patients présentant des erreurs de diagnostic potentielles en utilisant les données du dossier médical électronique (DME). Cependant, leurs valeurs prédictives sont faibles et ce processus nécessite un examen manuel fastidieux des dossiers médicaux pour confirmer les occasions manquées de diagnostic (OMD). Étant donné que les e-triggers sont conçus à l'aide d'hypothèses a priori plutôt que de modèles de données empiriques, ils peuvent ne pas détecter les signaux OMD de manière exhaustive. Nous avons testé si l'apprentissage automatique (ML) peut améliorer les performances des e-triggers et imiter les examinateurs de dossiers médicaux humains à plus grande échelle.
L'apprentissage automatique a amélioré la précision des déclencheurs électroniques pour identifier les MOD. Cette amélioration de l'apprentissage automatique pourrait améliorer la capacité d'une organisation à surveiller les erreurs de diagnostic à des fins de recherche, d'apprentissage et d'amélioration de la qualité. De plus, elle réduit considérablement la charge de travail de l'examen manuel des dossiers médicaux par le clinicien. Les limites de cette étude incluent le temps nécessaire pour préparer les variables utilisées par l'apprentissage automatique, bien qu'une fois cette étape terminée, l'algorithme puisse fonctionner à grande échelle. Le petit nombre de dossiers étiquetés par des experts peut limiter la capacité de l'apprentissage automatique à utiliser toutes les données structurées et à estimer les performances des ensembles de tests.
Les prochaines étapes incluent l'intégration du texte des notes cliniques comme source de prédiction des occasions manquées pour exploiter les riches données cliniques nécessaires à la détermination des MOD, l'augmentation du nombre de dossiers étiquetés par des experts sur lesquels l'approche est testée et la validation dans une population externe indépendante. L'apprentissage automatique s'avère prometteur en tant qu'outil permettant d'identifier efficacement les erreurs de diagnostic pour la recherche et l'amélioration de la qualité
Auerbach AD. Jeter les bases de l'utilisation de l'intelligence artificielle dans le diagnostic. JAMA Netw Open. 2024;7(9):e2431907.
Publié : 9 septembre 2024. est ce que je:10.1001/jamanetworkopen.2024.31907
Accès libre : il s'agit d'un article en accès libre distribué selon les termes de la licence CC-BY . © 2024 Auerbach AD. JAMA Network Open .
Auteur correspondant : Andrew D. Auerbach, MD, MPH, Université de Californie, San Francisco, UCSF Box 0131, San Francisco, CA 94143-0131 (
Commentaire
Médecine et IA, un partenariat harmonieux, une synergie obligatoire entre le médecin et l'IA.
Le médecin décide , l'IA accomplit la tâche demandée
Est ce que le robot remplacera un médecin , NON !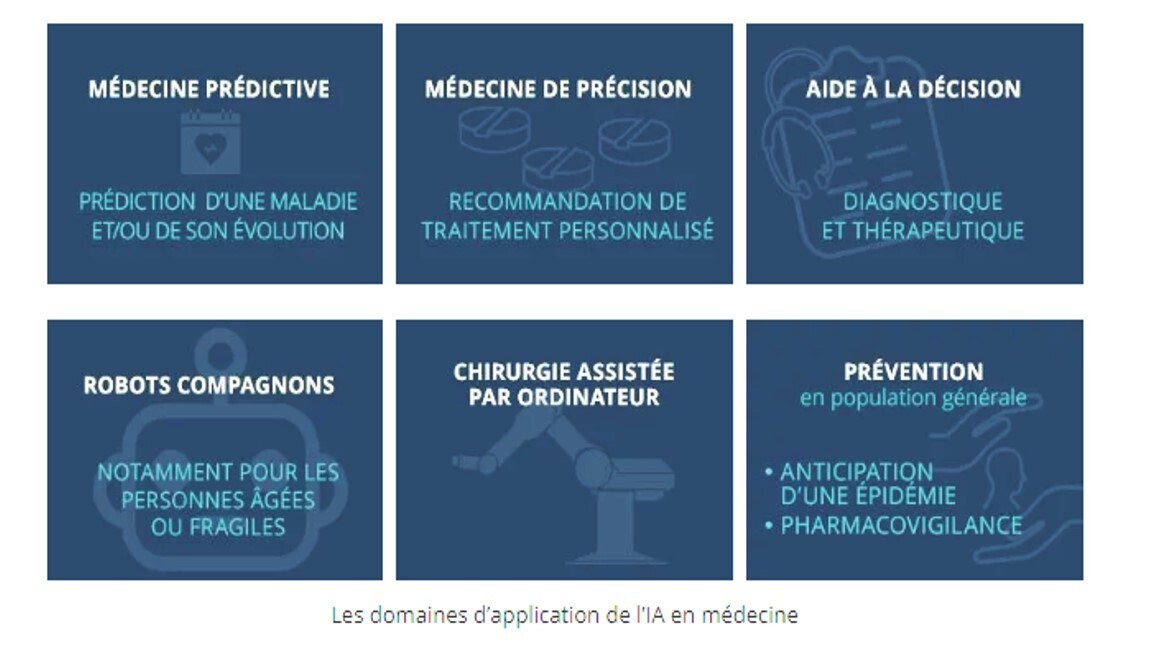
Avis de Gemini

L'évolution de la médecine grâce à l'intelligence artificielle (IA) est une révolution en marche, transformant profondément la manière dont nous diagnostiquons, traitons et prévenons les maladies.
Voici quelques domaines clés où l'IA apporte des avancées significatives :
-
Diagnostic médical amélioré
- Analyse d'images médicales : L'IA excelle dans l'identification de anomalies subtiles sur les radiographies, IRM, tomodensitogrammes, etc., permettant des diagnostics plus précis et plus rapides.
- Aide à la décision clinique : Les algorithmes d'IA peuvent analyser de vastes quantités de données de patients pour identifier des modèles et proposer des diagnostics différentiels, soutenant ainsi le médecin dans sa prise de décision.
-
Traitements personnalisés
- Médecine de précision : L'IA permet d'identifier des biomarqueurs spécifiques à chaque patient, ouvrant la voie à des traitements ciblés et plus efficaces.
- Optimisation des dosages médicamenteux : Les algorithmes d'IA peuvent prédire la réponse individuelle aux traitements, réduisant ainsi les effets secondaires et améliorant l'efficacité thérapeutique.
-
Découverte de nouveaux médicaments
- Accélération de la recherche : L'IA peut analyser de vastes bases de données moléculaires pour identifier de nouvelles cibles thérapeutiques et concevoir de nouvelles molécules.
- Simulation de molécules : Les modèles d'IA permettent de simuler l'interaction entre les molécules et les protéines, accélérant le processus de découverte de médicaments.
-
Prévention des maladies :
- Analyse prédictive : L'IA peut identifier les personnes à risque de développer certaines maladies en analysant leurs données de santé et leurs habitudes de vie.
- Suivi à distance : Les dispositifs médicaux connectés et les applications mobiles, alimentés par l'IA, permettent un suivi continu de la santé des patients et une détection précoce des problèmes.
-
Chirurgie assistée par robot
- Précision accrue : Les robots chirurgicaux guidés par l'IA offrent une précision inégalée, permettant des interventions moins invasives et une récupération plus rapide.
- Formation des chirurgiens : La simulation chirurgicale basée sur l'IA permet aux chirurgiens de se former dans un environnement virtuel réaliste.
Les défis et enjeux de l'IA en médecine
- Qualité des données : La performance des algorithmes d'IA dépend de la qualité et de la quantité des données utilisées pour leur entraînement.
- Ethique : L'utilisation de l'IA en médecine soulève des questions éthiques importantes, notamment en matière de confidentialité des données, de biais algorithmiques et de responsabilité en cas d'erreur.
- Intégration dans les systèmes de santé : L'intégration de l'IA dans les systèmes de santé existants nécessite des investissements importants et une adaptation des pratiques médicales.
En conclusion, l'intelligence artificielle est en passe de transformer en profondeur le paysage médical. Bien que des défis restent à relever, les avantages potentiels de l'IA en termes de diagnostic, de traitement et de prévention des maladies sont immenses.
Pour aller plus loin, je vous invite à consulter les ressources suivantes :