« Vers 2029, l’IA atteindra le niveau de l’intelligence humaine. Continuez jusqu’à 2045, et nous aurons amplifié l’intelligence – celle de notre civilisation humaine et machine – par un milliard de fois. » – Ray Kurzweil, inventeur et futurologue.
« Certains parlent d’intelligence artificielle, mais la réalité est que cette technologie va nous améliorer. Donc, au lieu d’intelligence artificielle, je pense que nous augmenterons notre intelligence. » – Ginni Romet
Perez-Lopez R, Ghaffari Laleh N, Mahmood F, Kather JN. A guide to artificial intelligence for cancer researchers. Un guide de l'intelligence artificielle pour les chercheurs en cancérologie
Nat Rev Cancer. 2024 Jun;24(6):427-441. doi: 10.1038/s41568-024-00694-7. Epub 2024 May 16. PMID: 38755439.
https://pubmed.ncbi.nlm.nih.gov/38755439/
Un article majeur pour toutes et tous ceux qui s'intéressent à l'IA et les applications IA dans le cancer
L’intelligence artificielle (IA) a été banalisée.
Elle est passé d'une ressource spécialisée à un outil facilement accessible pour les chercheurs en cancérologie.
Les outils basés sur l'IA peuvent augmenter la productivité de la recherche dans les flux de travail quotidiens, mais peuvent également extraire des informations cachées des données existantes, permettant ainsi de nouvelles découvertes scientifiques.
Construire une alphabétisation de base sur ces outils est utile pour tout chercheur en cancérologie.
Les chercheurs axés sur les sciences biologiques traditionnelles peuvent utiliser des outils basés sur l'IA via des logiciels disponibles dans le commerce, tandis que ceux qui sont plus enclins à l'informatique peuvent développer leurs propres pipelines logiciels basés sur l'IA.
Dans cet article, les auteurs proposent un guide pratique permettant aux chercheurs non spécialisés en informatique sur le cancer de comprendre comment les outils basés sur l’IA peuvent leur être bénéfiques.
Sont analysés les principes généraux de l'IA pour les applications dans l'analyse d'images, le traitement du langage naturel et la découverte de médicaments.
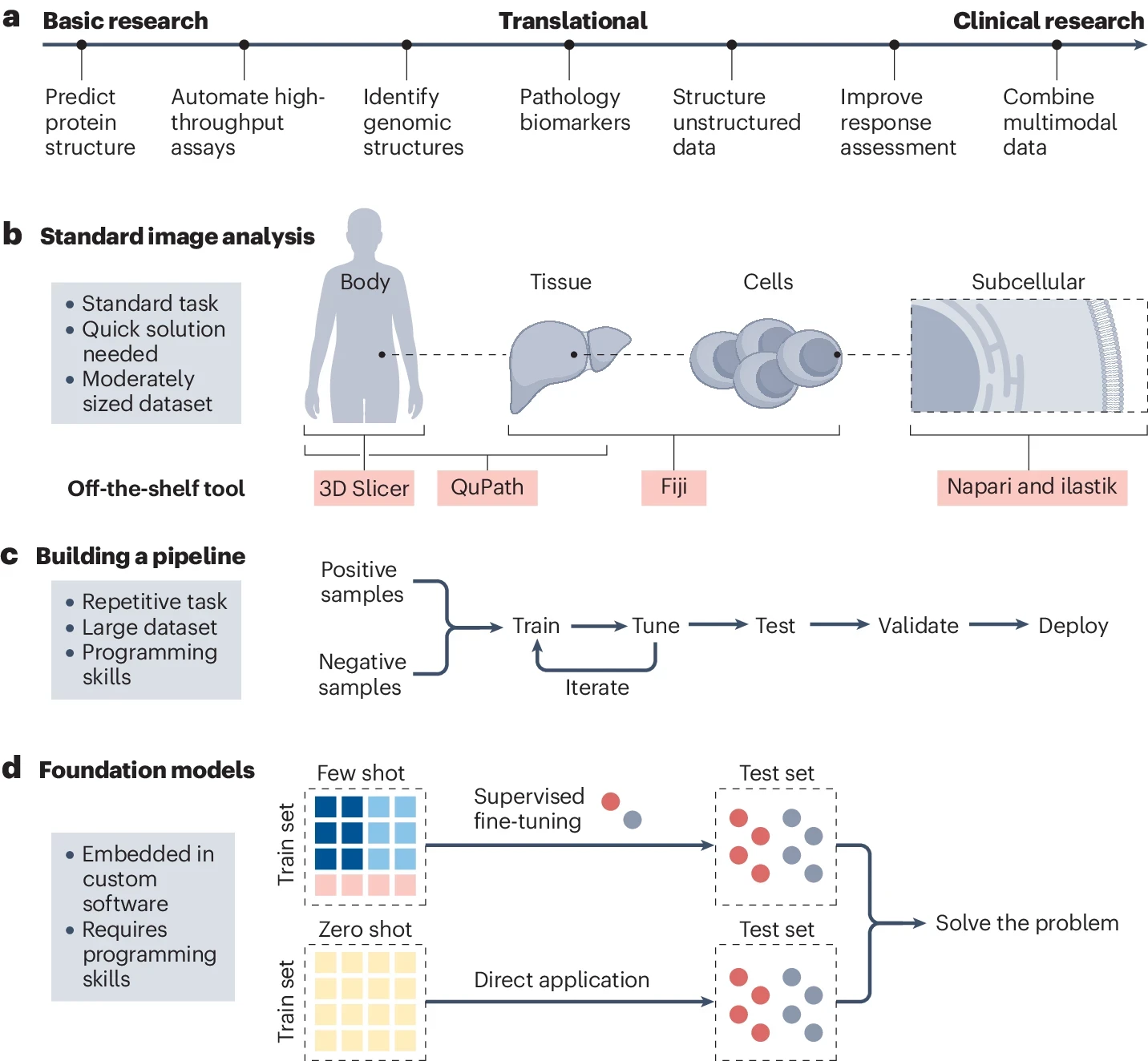
b , Les tâches standard d'analyse d'images telles que le comptage de cellules ou la segmentation des régions d'intérêt (ROI) nécessitent souvent des solutions rapides avec des outils disponibles dans le commerce. De nombreux outils open source sont disponibles pour accomplir ces tâches. Par exemple, ilastik est bien adapté à l’analyse subcellulaire, tandis que QuPath et 3D Slicer sont couramment utilisés respectivement pour l’imagerie au niveau des tissus et du corps entier. Fiji, ImageJ et CellProfiler sont des outils polyvalents capables de gérer un large éventail de tâches d'analyse d'images à différentes échelles. Une sélection de ces outils est présentée dans le tableau supplémentaire
c , Une autre catégorie de tâches d'analyse d'images implique celles qui nécessitent un processus itératif de formation et de réglage fin sur de vastes ensembles de données. Ces outils sont généralement très spécifiques à une tâche et sont conçus pour répondre à une question particulière. Construire, former et valider ces pipelines nécessite des compétences en programmation.
d , L'avenir de l'analyse d'images s'oriente vers des modèles de base, qui sont formés sur des ensembles de données étendus et hétérogènes et peuvent être affinés sur de nombreuses tâches. Dans l'apprentissage zéro-shot, le modèle est appliqué directement à l'ensemble de test sans aucune formation spécifique à la tâche, tandis que dans l'apprentissage en quelques-shots, le modèle est fourni avec un petit nombre d'exemples étiquetés pour s'adapter à la tâche spécifique.
Évolution de l’IA de la théorie à l’application pratique
Le domaine de l'intelligence artificielle (IA) est largement considéré comme issu d'une conférence au Dartmouth College en 1956. Les premiers travaux se sont concentrés sur ce que l'on appelle l'IA symbolique, comme les systèmes basés sur des règles pour des tâches telles que jouer aux échecs.
Dans les années 1960 et 1970, il est devenu plus courant d’incorporer des algorithmes d’apprentissage automatique et des réseaux de neurones artificiels simplistes, même si ceux-ci étaient limités en termes de calcul.
L’apprentissage automatique a aujourd’hui remplacé l’IA symbolique dans pratiquement toutes les applications avancées de l’IA, y compris dans la recherche sur le cancer.
Dans les années 1980, le développement de l’algorithme de rétropropagation a amélioré l’efficacité de la formation des réseaux de neurones artificiels. Malgré ces progrès, la recherche sur l’IA a connu une période hivernale à la fin des années 1980 et dans les années 1990 en raison d’attentes non satisfaites et des réductions de financement qui ont suivi.
L’attention s’est ensuite portée sur les techniques d’apprentissage automatique, telles que les machines à vecteurs de support ou les arbres de décision, qui ont démontré des performances statistiquement significatives dans diverses applications. Aujourd’hui, nous appelons ces méthodes d’apprentissage automatique « classiques ».
Néanmoins, les réseaux de neurones artificiels se sont encore développés et, finalement, au début des années 2010, les réseaux de neurones profonds ont démontré des performances remarquables dans des domaines tels que la reconnaissance d’images et de parole.
L'une des premières applications concrètes des réseaux de neurones a été celle des services postaux. Dans les années 1980, des réseaux de neurones artificiels étaient déjà utilisés pour automatiser le tri du courrier postal en reconnaissant les lettres manuscrites sur les enveloppes 168 . Aujourd’hui, l’apprentissage profond est répandu et facilite le diagnostic du cancer grâce à l’analyse d’images, à la détection des fraudes financières et à la navigation dans les véhicules autonomes. L’IA est passée d’une discipline théorique à un outil pratique ayant un effet transformateur sur diverses industries. Ses capacités vont désormais de la reconnaissance de formes de base aux réseaux neuronaux avancés capables d'apprendre sans supervision et de traiter le langage naturel en temps réel. Qu’il s’agisse de maisons intelligentes qui s’adaptent à nous ou d’algorithmes de recommandation qui anticipent nos préférences, la valeur de l’IA pour résoudre des problèmes complexes s’est avérée énorme et son influence continue de s’étendre.
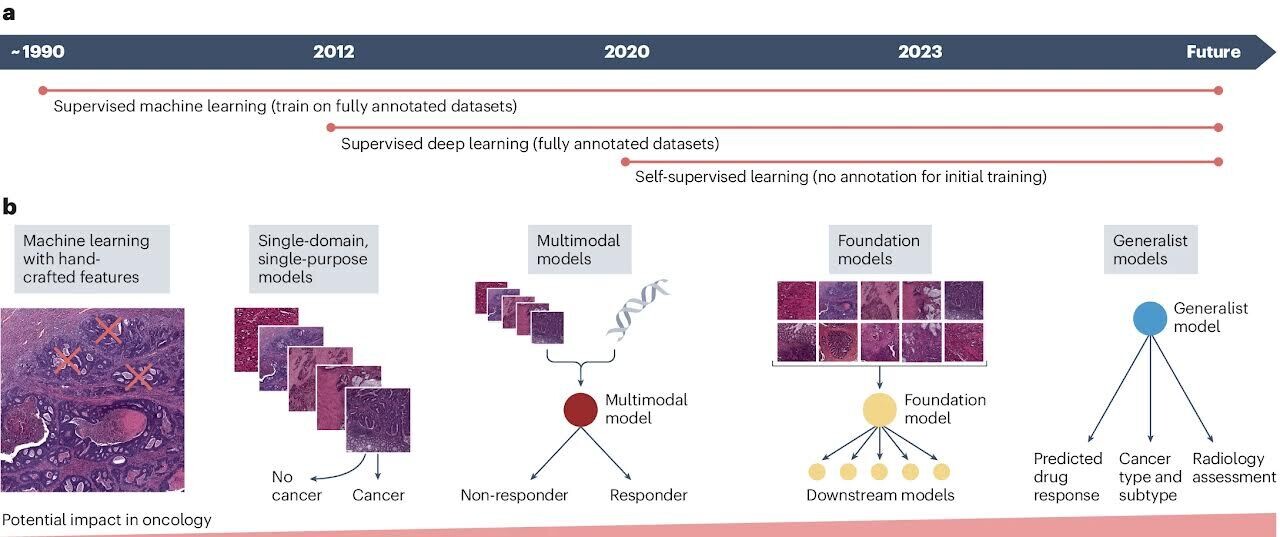
a Les progrès des techniques d'intelligence artificielle (IA) en imagerie médicale ont commencé à être largement utilisés avec l'apprentissage supervisé utilisant des modèles d'apprentissage automatique dotés de fonctionnalités artisanales au début des années 2000. Ces modèles s'appuyaient sur l'expertise du domaine pour extraire manuellement les caractéristiques pertinentes des images, qui étaient ensuite utilisées pour entraîner les modèles sur des ensembles de données étiquetés. Vers 2012, l'apprentissage profond supervisé a émergé, dans lequel des modèles d'IA, en particulier des réseaux de neurones convolutifs (CNN), ont été formés sur de grands ensembles de données étiquetés pour apprendre automatiquement des caractéristiques hiérarchiques directement à partir de données d'images brutes. Cette approche a considérablement amélioré les performances et la généralisabilité des modèles d’IA dans les tâches d’imagerie médicale. Au début des années 2020, de nombreux groupes de recherche ont commencé à utiliser les nouvelles méthodes d’apprentissage auto supervisé, qui permettent aux modèles d’apprendre des modèles significatifs à partir de données non étiquetées en prédisant les propriétés des données elles-mêmes, sans s’appuyer sur des étiquettes externes.
Gains de productivité grâce au deep learning
Au-delà des applications directes de recherche, l’apprentissage profond transforme les flux de travail de recherche en optimisant les tâches quotidiennes. Les chercheurs peuvent utiliser l’intelligence artificielle (IA) pour des tâches administratives, telles que la rédaction de réponses standard par courrier électronique ou la création de croquis visuels. Selon un rapport de McKinsey de 2023 intitulé The Economic Potential of Generative AI: The Next Productivity l'IA générative pourrait affecter entre 2,6 % et 4,5 % des revenus annuels du secteur de la santé et de l'industrie pharmaceutique, ce qui se traduirait par une valeur supplémentaire annuelle entre 60 milliards de dollars et 110 milliards de dollars à l’échelle mondiale. De même, une étude récente du Boston Consulting Group a conclu que l’IA rendait les consultants en gestion nettement plus productifs en utilisant de grands modèles de langage dans des tâches de routine impliquant la génération de texte . Bien qu’il s’agisse de projections et non de certitudes, elles pourraient être extrapolées aux chercheurs individuels qui pourraient devenir plus productifs en intégrant des méthodes d’IA dans leurs flux de travail quotidiens.
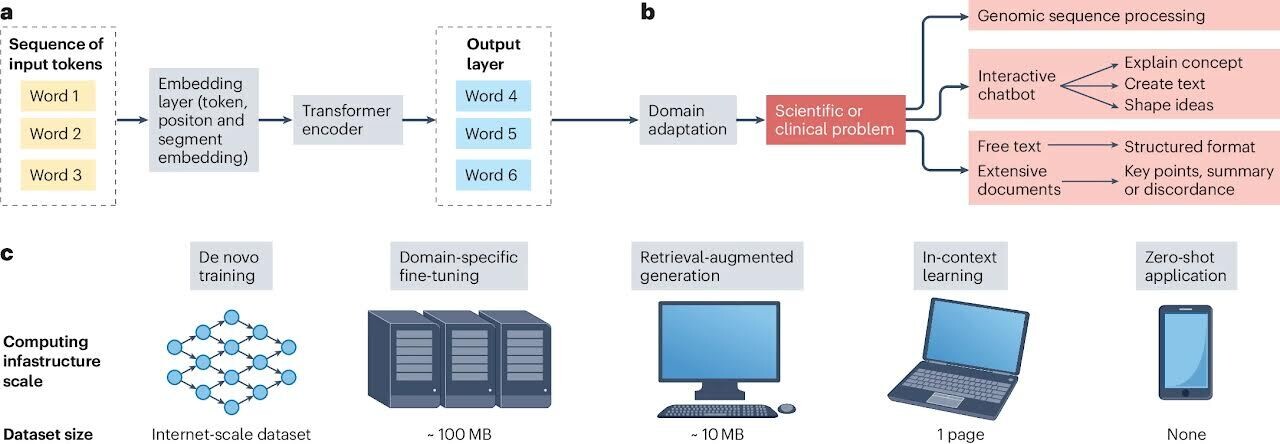
a , L'évolution des modèles de traitement du langage naturel (NLP) a vu un passage des architectures de réseaux neuronaux récurrents (RNN) aux architectures de transformateur. Dans ces modèles de transformateur, les jetons d'entrée (par exemple, les mots) sont d'abord convertis en vecteurs via une partie cruciale du modèle NLP : la couche d'intégration. Ici, des mots ou des phrases sont transformés en représentations numériques, permettant au modèle de traiter le langage. Ces vecteurs, ainsi que les incorporations de positions et de segments (qui ajoutent des informations contextuelles sur l'ordre et la relation des jetons), sont ensuite transmis via des « encodeurs de transformateur ». Les encodeurs de transformateur sont des composants avancés du modèle qui traitent l'entrée en considérant le contexte de chaque mot par rapport aux autres, permettant ainsi au modèle de comprendre des modèles de langage complexes. La couche de sortie du modèle de transformateur génère les prédictions ou représentations finales basées sur l'entrée traitée, qui peuvent être utilisées pour diverses tâches en aval telles que la classification de texte, la reconnaissance d'entités nommées ou la génération de texte.
b , Les modèles PNL entraînés peuvent être appliqués à diverses tâches de recherche sur le cancer. Par exemple, ils peuvent convertir des notes cliniques ou des documents de recherche non structurés en formats structurés, rendant ainsi les informations plus facilement accessibles et analysables. Ceci peut être réalisé en entraînant le modèle sur un vaste corpus de données textuelles annotées, dans lequel le format structuré souhaité est fourni sous forme d'étiquettes. Le modèle apprend à identifier les informations clés et à les mapper aux champs appropriés dans le format structuré. Les modèles PNL peuvent également résumer de longs documents, tels que des articles de recherche ou des rapports d'essais cliniques, en soulignant les points et les résultats clés.
c, La formation et le réglage fin de ces modèles dépendent de la taille de l'ensemble de données et de la puissance de calcul. La formation de novo de grands modèles linguistiques (LLM) nécessite des ensembles de données à l'échelle Internet, contenant des milliards de mots, et une infrastructure informatique massive. Cependant, une fois ces grands modèles pré-entraînés, ils peuvent être ajustés pour des tâches spécifiques en utilisant des ensembles de données spécifiques à un domaine beaucoup plus petits, souvent de l'ordre de quelques centaines à quelques milliers d'exemples. Ce processus de réglage fin est moins exigeant en termes de calcul et peut être effectué sur une infrastructure à plus petite échelle. Pour certaines tâches, les LLM peuvent être utilisés de manière « zéro-shot », dans laquelle ils effectuent la tâche sans aucune formation supplémentaire, en s'appuyant uniquement sur leurs connaissances préexistantes. Cette capacité de zéro tir permet aux LLM d'être appliqués à un large éventail de tâches, même sur des appareils aux ressources limitées tels que les téléphones mobiles. L'apprentissage en contexte et la génération augmentée par récupération (RAG) sont des approches alternatives, dans lesquelles le modèle reçoit respectivement quelques exemples de la tâche souhaitée dans le cadre de l'invite de saisie ou en fournissant au modèle des documents supplémentaires, lui permettant de s'adapter à la tâche sans réglage explicite. Ces différentes approches ont rendu les capacités de compréhension et de génération du langage plus accessibles et plus efficaces.
Des LLM multimodaux à l’IA médicale généraliste
Les grands modèles de langage (LLM), dans leur forme la plus simple, sont réservés au texte. Cependant, depuis 2022, les LLM ont considérablement évolué, aboutissant à des LLM multimodaux intégrant le traitement de texte et d’images. Ces modèles peuvent être conçus comme des entités singulières dotées de capacités de perception d’image et de texte, ou comme des parties distinctes de traitement d’image et de codage de texte fusionnées. Par exemple, la version actuelle du populaire LLM chatGPT accepte les images ainsi que le texte en entrée. Cette approche multimodale brouille les frontières entre le traitement du langage naturel et la vision par ordinateur, offrant des compétences supérieures en matière de reconnaissance de formes et d'analyse 96 , 171 . Dans la recherche sur le cancer, ces avancées sont particulièrement prometteuses. Les modèles multimodaux peuvent désormais analyser des images histopathologiques complexes et engager des interactions conversationnelles
En fin de compte, ces modèles peuvent être formés sur divers types de données et offrir une solution unifiée pour diverses tâches, telles que l’interprétation des images microscopies et radiographiques et le traitement des notes cliniques. Cependant, bien que la technologie existe et progresse rapidement, plusieurs défis pratiques et réglementaires subsistent 172 . Sur la base de ces LLM multimodaux, des approches d’apprentissage zéro-coup et quelques coups peuvent être utilisées pour traiter les images.
Le but ultime du deep learning est de développer un modèle multimodal et multitâche unique capable d’aborder simultanément un large éventail de tâches. Un tel modèle serait véritablement « généraliste » 96 . Par exemple, au lieu d’avoir trois modèles distincts pour l’analyse d’images radiologiques, l’analyse d’images pathologiques et l’analyse de données génomiques, un seul modèle pourrait intégrer les informations de toutes ces modalités et produire une seule prédiction. Cela réduirait le nombre de modèles nécessaires aux flux de travail de recherche et augmenterait leurs performances en exploitant les synergies entre les types de données. Au cours des dernières années, de premières études de validation de principe ont montré que de telles synergies existent entre les données génomiques et histologiques 48 , 173 , la radiologie et l'histologie 130 , la radiologie et les données cliniques 83 et entre différentes colorations histologiques 129 . Ces études récentes ne sont que le début d’une tendance plus large allant des modèles monomodaux à objectif unique vers des modèles multimodaux à objectifs multiples.
En élargissant cela, des modèles d'apprentissage profond généralistes pourraient permettre une interaction utilisateur de type LLM pour rendre les prédictions du modèle plus explicables. En intégrant des fonctionnalités de PNL, les modèles généralistes pourraient fournir des explications intuitives pour leurs prédictions, de la même manière que les LLM peuvent générer un texte lisible par l'homme. Plus précisément, le concept relativement nouveau d’IA médicale généraliste (GMAI) pourrait avoir un impact sur la recherche sur le cancer dans les années à venir 96 . La compétence du GMAI dans le traitement de divers types de données, de l'imagerie à l'information génétique, pourrait considérablement améliorer les méthodes de diagnostic et de pronostic en oncologie. Le passage de modèles spécifiques à des tâches à une approche plus holistique et intégrée pourrait marquer une transformation substantielle dans l’application de l’IA dans la recherche sur le cancer et l’oncologie.
Glossaire
- Interface de programmation d'applications
-
(API). Un ensemble d'outils et de protocoles pour créer des logiciels et des applications, permettant aux logiciels de communiquer avec des modèles d'IA.
- Réseaux de neurones artificiels
-
(ANN). Modèles informatiques vaguement inspirés de la structure et du fonctionnement du cerveau humain, constitués de couches de nœuds interconnectés, appelés neurones, qui traitent les données d'entrée et apprennent à reconnaître des modèles et à prendre des décisions.
- Pathologie informatique
-
L'utilisation d'algorithmes, de techniques d'apprentissage automatique et d'analyse d'images pour extraire des informations à partir d'images de pathologie numériques.
- Vision par ordinateur
-
Un domaine de l'IA qui vise à permettre aux ordinateurs d'analyser et d'interpréter des données visuelles, telles que des images et des vidéos.
- Réseaux de neurones convolutifs
-
(CNN). Un type de réseau neuronal profond particulièrement efficace pour analyser l’imagerie visuelle et utilisé dans l’analyse d’images.
- L'apprentissage en profondeur
-
L'apprentissage profond est un sous-domaine de l'apprentissage automatique qui utilise des réseaux de neurones artificiels à plusieurs couches, appelés réseaux de neurones profonds, pour apprendre et extraire des caractéristiques et des modèles très complexes à partir de données d'entrée brutes.
- Images numériques
-
Représentations visuelles capturées et stockées dans un format numérique, constituées d'une grille de pixels, chaque pixel représentant une valeur d'intensité de couleur.
- Pathologie numérique
-
Pratique consistant à convertir des lames de verre en lames numériques pouvant être visualisées, gérées et analysées sur un ordinateur.
- Méthodes d'explicabilité
-
Techniques d'IA qui fournissent des informations et des explications sur la manière dont le modèle d'IA est arrivé à ses conclusions, rendant ainsi le processus décisionnel de l'IA plus transparent.
- IA générative
-
Des systèmes d’IA capables de générer un nouveau contenu (texte, images ou musique) similaire au contenu sur lequel ils ont été formés, créant souvent des résultats nouveaux et cohérents.
- Images gigapixels
-
Images numériques de très haute résolution composées de 1 milliard de pixels, obtenues en numérisant des lames de tissus avec un scanner de lames.
- Unités de traitement graphique
-
(GPU). Matériel spécialisé utilisé pour traiter rapidement et simultanément de gros blocs de données, utilisé dans les jeux informatiques et l’IA.
- Grands modèles de langage
-
(LLM). Modèles d'IA avancés formés sur de grandes quantités de données textuelles, capables d'analyser, de générer et de manipuler le langage humain, souvent au niveau humain 174 .
- Réseaux de mémoire à long terme (LSTM)
-
Type de réseau neuronal particulièrement efficace pour traiter des séquences de données (telles que des séries temporelles ou un langage), avec la capacité de mémoriser des informations pendant un certain temps.
- Apprentissage automatique
-
Sous-ensemble de l'IA axé sur le développement d'algorithmes et de modèles permettant aux ordinateurs d'apprendre et d'améliorer leurs performances sur une tâche spécifique sans recevoir d'instructions explicites sur la manière d'y parvenir.
- Traitement du langage naturel
-
(PNL). Une branche de l'IA qui aide les ordinateurs à analyser, interpréter et répondre au langage humain de manière utile.
- Ingénierie rapide
-
Élaborer des entrées ou des questions de manière à guider les modèles d'IA, en particulier les LLM, pour fournir les réponses les plus efficaces et les plus précises.
- Transformateurs
-
Types de modèles de réseaux neuronaux qui excellent dans le traitement de séquences de données, telles que des phrases dans un texte, en se concentrant sur différentes parties de la séquence pour faire des prédictions 175 .
- Voxel
-
L'équivalent tridimensionnel d'un pixel dans les images, représentant une valeur sur une grille régulière dans un espace tridimensionnel, couramment utilisé en imagerie médicale telle que l'IRM et la tomodensitométrie.
CONCLUSION des auteurs
Un défi majeur dans l’application de l’IA à la recherche sur le cancer réside dans l’exploitation du potentiel des données du monde réel (RWD) en oncologie, qui comprennent les DSE, les images médicales, les échantillons de tumeurs et les analyses de sang 164 . Contrairement aux données des essais cliniques, qui sont collectées de manière prospective selon des protocoles bien définis et structurées dans des bases de données facilement accessibles, les RWD sont souvent non structurées, hétérogènes et dispersées dans différents systèmes. Les systèmes de DSE (dossiers médicaux électroniques)constituent une source de données particulièrement intéressante pour les systèmes réels basés sur l'IA . L’analyse basée sur l’IA des données cliniques de routine est également prometteuse pour la médecine personnalisée. Faire progresser l’oncologie de précision nécessitera le développement d’un plus grand nombre de biomarqueurs plus précis pour prédire la réponse au traitement, l’identification de nouvelles cibles médicamenteuses dans les cellules cancéreuses et une plateforme de développement accéléré de médicaments pour simplifier la correspondance entre les cibles et les médicaments. Ici, l’IA pourrait découvrir des modèles cachés dans le profilage moléculaire pour faire avancer ces choses. Bien que l’IA ait été largement utilisée pour découvrir des modèles de profilage moléculaire des tumeurs associés aux résultats cliniques, tels que le pronostic et la réponse thérapeutique , traduire ces résultats dans la pratique clinique reste un défi. Cela est dû en partie à la complexité de la biologie du cancer, à l’hétérogénéité des populations de patients et à la nécessité d’une validation rigoureuse des biomarqueurs et des cibles médicamenteuses dérivés de l’IA. Pour réaliser pleinement le potentiel de l’IA dans l’avancement de l’oncologie de précision, plusieurs défis clés doivent être relevés. Celles-ci incluent l’intégration de multiples modalités de données (par exemple, imagerie, données génomiques et cliniques), le développement de modèles d’IA explicables et transparents et l’établissement de normes pour le partage de données et la validation des modèles. En outre, une collaboration plus étroite entre les chercheurs en IA, les biologistes du cancer et les cliniciens sera essentielle pour garantir que les outils basés sur l’IA sont cliniquement pertinents et adaptés aux besoins des patients et des prestataires de soins de santé. Les progrès rapides de l’IA, entraînés par des améliorations substantielles du matériel et des algorithmes, laissent présager un avenir passionnant. Il est conseillé aux chercheurs en cancérologie de se familiariser avec ces outils et de développer une intuition sur le potentiel et les limites de l’IA contemporaine afin de pouvoir naviguer dans un monde dans lequel les outils basés sur l’IA sont omniprésent
REMARQUEProblèmes
Les algorithmes produits par l’IA ne sont pas dépourvus de difficultés sur le plan médical, éthique et social, certaines étant causées par les valeurs des rédacteurs des données (p. ex. médecins), des concepteurs et des sources de financement et d’autres, parce que les entrées dans les DME ne sont ni uniformisées ni rédigées pour répondre à des questions de recherche.Les renseignements consignés dans les DME sont circonscrits par l’accès des patients aux soins (pas de rencontre clinique signifie pas de consignation de données sur ce patient), et par les valeurs et les déterminations des cliniciens au sujet de ces soins. L’ambiguïté, l’absence de terminologie normalisée, les inexactitudes et les acronymes portant à confusion sont inévitables. Les données des DME sont limitées par la longévité du dossier et peuvent être faussées pour de nombreuses raisons, y compris une mesure ou une documentation incohérente des biomarqueurs, l’absence de qualificatif au diagnostic, comme la sévérité, ou même une orthographe impossible interpréter. Pour fusionner les facteurs sociaux et biologiques connus de la santé, l’IA exige la disponibilité et la précision des paramètres sociodémographiques, comme la race et la situation socioéconomique, des données qui ne sont pas systématiquement inscrites dans les DME au Canada. Cette lacune signifie que les algorithmes doivent soit ignorer ces données ou encore risquer d’imputer ces catégories.
En outre, les diagnostics consignés, même à l’aide des codes CIM, sont souvent vagues (p. ex. une entrée « cancer du sein »réfère-t-elle à la crainte de la patiente, au sujet d’une discussion ou à un diagnostic?), comme peuvent l’être des mots tels que pire et mieux. Les algorithmes pourraient ne se servir que des mesures biomédicales sans tenir compte des déterminants sociaux, mais une telle omission pourrait réduire les « promesses » de l’IA et entraîner un aveuglement néfaste quant aux effets médicaux des conditions sociales Les médecins tiennent probablement en compte les déterminants sociaux de la santé d’un patient en plus de ses problèmes de santé; sinon, cela pourrait nuire à au plus un patient. L’agrégation des données des DME pour prédire les risques pour la santé multiplie l’effet d’aveuglement envers les caractéristiques sociodémographiques et peut nuire à l’exactitude des prédictions pour de nombreux patients
Ce n’est que lorsque nous aurons l’assurance que les valeurs de l’IA, de même que la formation et les ensembles de données de validation sous-jacents sont alignés sur les entités qu’ils prétendent aider, et sont aussi larges et inclusifs que ces dernières, que leurs modalités favoriseront l’équité sociale et raciale, et une meilleure santé pour tous.
La vraie question est de savoir si les responsables de la réglementation, les scientifiques spécialistes des données, les chercheurs en médecine et les cliniciens donneront la priorité à l’équité et à l’éthiqueCanadian Family Physician | Le Médecin de famille canadien } Vol 68: AUGUST | AOÛT 2022
Nous entrons dans une oncologie de précision et prédictive, une oncologie millimétrée
Mais attention il y a aura toujours face au médecin un patient qui souffre, qui est en état de détresse. Ce patient est un humain qui a besoin d'humanité, d'écoute, de respect, de compassion, d'empathie d'éthique, de tolérance. Tout ceci reste et doit rester du domaine médical hors machine
Mais attention aussi à l'arrivée d'un nouveau paradigme IA dépendant, l'IA à moyen terme pourra annoncer avec une très grande précision la fin de vie et ce n'est pas de la science fiction.
La boîte de Pandore n'est jamais loin !
Quid des lois à venir sur la fin de vie et de l'intelligence artificielle ?
Enfin dernier point l'IA poussée à son maximum est à l'origine d'une augmentation à priori d'une importante de l'empreinte carbone. donc un usage responsable et approprié de l'IA au regard des enjeux environnementaux et sociaux et de l’intérêt général est indispensable !
https://www.lecese.fr/travaux-du-cese/saisines/intelligence-artificielle-et-environnement
A LIRE
CLIMAT, ÉNERGIE, RÉSILIENCE : En partenariat avec DÉCARBONONS LES INDUSTRIES DE SANTÉ FOCUS MÉDICAMENTS - PRÉPARATOIRE AUX TRAVAUX ÉVALUANT L’IMPACT CARBONE DES MÉDICAMENTS, DES DISPOSITIFS MÉDICAUX ET LEURS LEVIERS DE DÉCARBONATION
