La promesse de l'intelligence artificielle (IA) d'améliorer et de réduire les inégalités en matière d'accès, de qualité et de pertinence d'un diagnostic de haute qualité reste largement non tenue.
De vastes ensembles de données cliniques, une capacité de calcul étendue et des outils d'apprentissage automatique hautement développés et accessibles ont donné lieu à de nombreuses publications qui décrivent des approches algorithmiques performantes pour une variété de tâches de diagnostic.
Cependant, de telles approches restent largement inadaptées dans la pratique clinique.
Cet écart entre la promesse et la pratique - le gouffre de l'IA - a de nombreuses causes.
Certaines raisons sont endémiques au domaine plus large de l'IA, notamment un manque de généralisabilité et de reproductibilité pour les algorithmes publiés.
D'autres raisons sont plus spécifiques à l'IA clinique, telles que le manque de diversité de genre, de race et d'ethnie dans les ensembles de données cliniques et une évaluation insuffisante des algorithmes en milieu clinique.
La déconnexion entre les mesures de performance des algorithmes et les réalités du flux de travail et du processus de prise de décision d'un clinicien est un problème fondamental mais souvent négligé.
L'inclusion du contexte clinique dans les mesures de performance de l'IA pour optimiser et évaluer les algorithmes cliniques pourrait rendre les outils d'IA plus pertinents sur le plan clinique et facilement adoptés
Points clés pour l'excellence du diagnostic
-
Les mesures de performance des algorithmes de diagnostic clinique intègrent rarement des fonctionnalités pertinentes pour l'utilité clinique et le flux de travail
-
Le développement et l'application de mesures cliniquement pertinentes peuvent affiner et améliorer l'adoption d'outils d'intelligence artificielle (IA) dans la pratique clinique
-
Les mesures de performance doivent évaluer explicitement le biais et l'équité dans les algorithmes de diagnostic
-
L'engagement entre les cliniciens et les développeurs d'algorithmes est essentiel pour développer des mesures cliniquement pertinentes
Les mesures de performance sont utilisées pour évaluer les modèles d'IA et faciliter l'interprétation et la hiérarchisation des modèles à usage clinique.
Par exemple, la sensibilité et la spécificité d'un test de diagnostic décrivent la précision du test pour détecter une maladie, et l'aire sous la courbe caractéristique de fonctionnement du récepteur reflète la capacité d'un modèle à différencier les patients en bonne santé des patients atteints d'une maladie ou d'une maladie.
Cependant, malgré l'utilisation de ces mesures et d'autres mesures traditionnelles dans les milieux cliniques, les mesures n'ont aucun contexte clinique : tous les diagnostics corrects sont traités comme également positifs, et tous les diagnostics incorrects sont considérés comme également négatifs. De plus, on ignore que certains algorithmes sont appliqués à plusieurs reprises pour suivre l'état d'un patient au fil du temps,
Peu de mesures de performance existantes intègrent le contexte clinique, et différents problèmes cliniques nécessitent des mesures différentes.
Deux de ces mesures, développées pour une série de compétitions publiques connues sous le nom de PhysioNet Challenges, illustrent ces problèmes.
Pour le défi PhysioNet 2019, les équipes ont été invitées à développer des algorithmes de prédiction précoce du sepsis. Les algorithmes ont effectué des prédictions de sepsie toutes les heures pour identifier les patients à traiter jusqu'à 12 heures avant la reconnaissance clinique de l'apparition de la sepsie. Une mesure de performance dépendante du temps a été conçue pour récompenser ou pénaliser les algorithmes, en fonction de l'utilité clinique de leurs prédictions et de leur probabilité d'améliorer les résultats pour les patients.
Cette métrique a fourni des scores élevés pour les prédictions précoces de sepsie afin de permettre une administration plus précoce de liquides et d'antibiotiques, avec des scores plus élevés pour les prédictions antérieures. La métrique a fourni des scores faibles pour les prédictions de sepsie tardives et manquées qui entraîneraient des traitements retardés. Il a également fourni des scores faibles pour les fausses alarmes qui ont réduit la confiance dans l'algorithme, mais moins que les prédictions de sepsie tardives et manquées. Les médecins de soins intensifs ont contribué à l'élaboration de cette mesure, qui quantifiait leurs préférences quant à la valeur d'un traitement précoce, leur capacité à retarder le traitement et la tolérance du personnel aux fausses alarmes. Les valeurs précises de ces quantités sont sujettes à débat, mais elles doivent être choisies pour refléter les besoins des utilisateurs des algorithmes.
Pour les challenges 2020 et 2021, les équipes ont été sollicitées pour développer des algorithmes permettant d'identifier 26 anomalies cardiaques à partir d'électrocardiogrammes (ECG). Les algorithmes ont signalé des conditions qui seraient ensuite suivies par des tests de confirmation, de sorte qu'une mesure de performance a été conçue pour encourager les diagnostics corrects mais fournir des scores différents pour différents diagnostics erronés.
Cette mesure a fourni des scores plus élevés pour les diagnostics erronés qui ont entraîné les mêmes tests de suivi et traitement que le diagnostic correct (par exemple, classer à tort la fibrillation auriculaire en tant que flutter auriculaire). Cependant, la métrique a fourni des scores beaucoup plus faibles pour manquer une arythmie plus cliniquement significative qui nécessiterait une attention urgente (par exemple, une classification erronée de la fibrillation ventriculaire en tant que fibrillation auriculaire). Les cardiologues ont participé à la création de cette métrique et ont défini des récompenses et des pénalités reflétant les risques et les similitudes diagnostiques de chaque paire d'anomalies cardiaques pouvant être diagnostiquées à partir de l'ECG.
Ces compétitions illustrent des exemples de modèles généralisables pour la conception de mesures de performance avec un contexte clinique. L'objectif n'est pas de remplacer entièrement les mesures de performance traditionnelles et universelles par un autre ensemble de mesures de ce type. Au lieu de cela, l'objectif est d'identifier les principales caractéristiques d'un problème clinique et de concevoir des mesures de performance qui améliorent l'utilité clinique des algorithmes pour les cliniciens qui les utilisent. Cela nécessite de travailler avec des cliniciens pour définir des objectifs cliniquement pertinents et pratiquement réalisables pour les algorithmes à optimiser. De multiples fonctions et contraintes de coût sont possibles et souvent nécessaires pour décrire des objectifs qualitativement différents, tels que la précision du diagnostic, la rapidité, les coûts des soins de santé et la capacité ;4 Le signalement des métriques nouvelles et traditionnelles facilite la caractérisation des compromis entre les métriques et aide l'utilisateur à comprendre pourquoi des valeurs de précision légèrement inférieures pourraient être tolérées pour réduire considérablement les biais ou les taux de fausses alarmes.
Il existe de nombreuses objections potentielles et raisonnables à l'introduction de nouvelles mesures de performance pour les tâches cliniques. Des métriques mal conçues peuvent causer plus de mal que de bien. Par exemple, les besoins en matière de santé sont corrélés aux coûts des soins de santé, et les coûts sont souvent plus faciles à quantifier. Cependant, l'optimisation directe des coûts des soins de santé plutôt que des besoins de santé peut contribuer aux disparités en matière de santé. 5L'optimisation aveugle des métriques de substitution peut être associée à des biais et à des inégalités, qui sont des problèmes qui doivent être explicitement pris en compte avec n'importe quelle métrique. Une prolifération de mesures de performance peut également entraver la comparaison d'interventions similaires. Cependant, le cadre commun fourni par les métriques traditionnelles est en partie une illusion, car les résultats pour la même métrique sur différentes bases de données ou tâches cliniques sont intrinsèquement incomparables.
Plusieurs suggestions peuvent être utiles aux cliniciens et aux décideurs qui conçoivent et utilisent des outils d'IA.
1/ Les cliniciens ne doivent pas supposer que les paramètres traditionnels, tels que la zone sous la courbe caractéristique de fonctionnement du récepteur, se traduisent par des effets cliniques, car ces paramètres de performance ne sont généralement pas optimisés ou évalués pour des contextes cliniques spécifiques.
2/ Les cliniciens devraient être impliqués dans l'orientation de la conception des métriques pour s'assurer que les algorithmes produisent des résultats cliniquement utiles et centrés sur le patient afin de minimiser les dommages imprévus.
3/ les cliniciens devraient donner la priorité à l'utilisation d'outils d'IA avec des explications bien documentées et compréhensibles des mesures de performance, car cela pourrait permettre de prendre des décisions éclairées sur l'opportunité et la meilleure façon d'utiliser l'algorithme.
4/ les cliniciens doivent s'attendre à une évaluation prospective des algorithmes en milieu clinique. L'évaluation dans divers contextes démontre l'utilité potentielle d'un algorithme pour les résultats cliniques réels.
5/ Les utilisateurs d'outils d'IA devraient exiger que les développeurs d'IA mettent à disposition le code complet d'un algorithme, y compris les données de formation et le code, afin que les métriques utilisées pour développer les algorithmes soient explicites et modifiables.
6/ Les mesures de performance diagnostique doivent tenir compte des performances différentielles dans les sous-groupes de population, en particulier pour les conditions qui peuvent se présenter différemment en fonction de la race, de l'origine ethnique ou du sexe.
Les cliniciens et autres décideurs en matière de soins de santé ont la responsabilité de choisir des algorithmes transparents, cliniquement utiles et efficaces pour diverses populations de patients.
Pour faciliter une décision éclairée, les équipes de développement d'algorithmes doivent également être diversifiées et travailler en étroite collaboration avec les cliniciens pour développer et mettre en œuvre des mesures de performance de l'IA qui intègrent le contexte clinique.
Ce processus devrait également reconnaître et refléter la diversité des objectifs et des parties prenantes en médecine diagnostique afin d'améliorer la pertinence et la représentation des outils d'IA dans la pratique clinique.
Commentaire
La Société Française de Médecine Vasculaire (SFMV) se doit d'avoir un groupe de travail IA et Médecine Vasculaire ou IA-MV . Reprenons le point important de cet article " pour faciliter une décision éclairée, les équipes de développement d'algorithmes doivent également être diversifiées et travailler en étroite collaboration avec les cliniciens pour développer et mettre en œuvre des mesures de performance de l'IA qui intègrent le contexte clinique".
Le médecin vasculaire ne doit pas se transformer en super informaticien. La SFMV, par le groupe IA-MV doit définir ses besoins qui peuvent être fournis par l'IA en colllaboration avec les développeurs d'algorithmes. Il ne faut pas passer à côté de l'IA. Au contraire la SFMV doit accompagner cette mutation de notre métier. Le clinicien doit être à la base de
ce raisionnement.
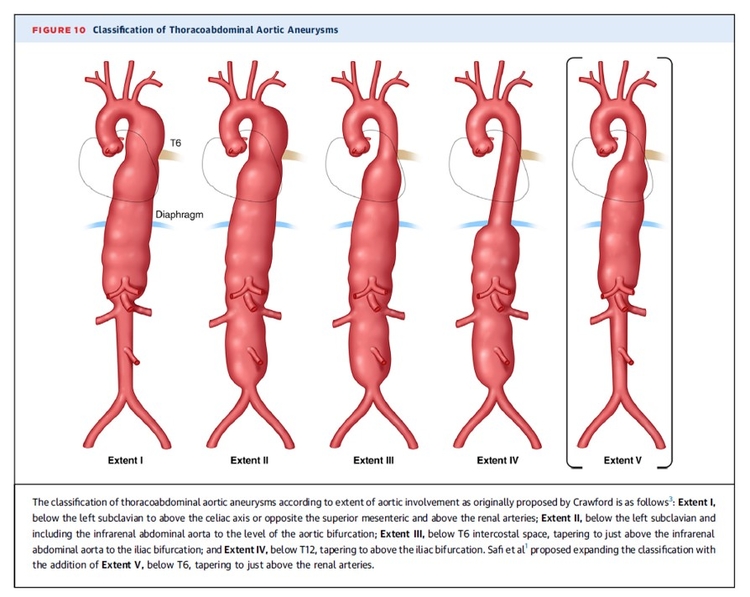
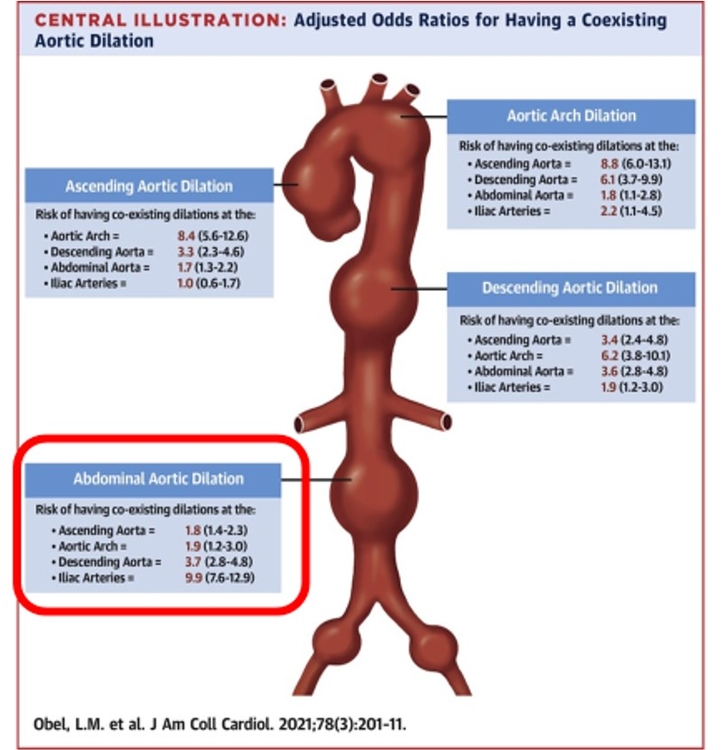
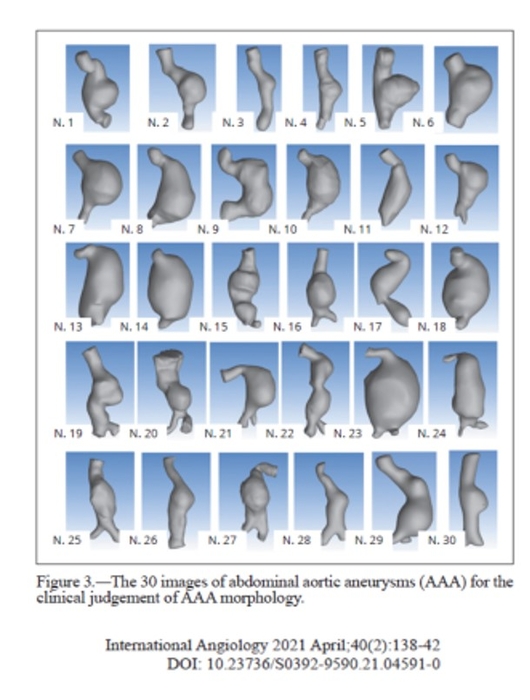
L'IA pourrait nous aider dans la prédiction de la récidive de la MTEV, mieux évaluer le risque hémorragique, mieux cibler les patients qui présentent une MTEV sans facteur déclenchant en orientant de manière individuelle le recherche du cancer. L'IA devrait être prédictive de la croissance d'un anévrisme de l'aorte abdominale et apprécier de manière précise le caractère vulnérable de la plaque carotidienne. Enfin le pronostic des troubles trophiques du pied chez le diabétique devrait pouvoir être amélioré.
Alors à quand l'IA-MV ?
Complément d'enquête
- https://www.cea.fr/comprendre/Pages/nouvelles-technologies/essentiel-sur-intelligence-artificielle.aspx
- https://www.college-de-france.fr/media/yann-lecun/UPL4485925235409209505_Intelligence_Artificielle______Y._LeCun.pdf
- https://www.cnil.fr/fr/intelligence-artificielle/intelligence-artificielle-de-quoi-parle-t-on
- https://medvasc.info/1929-l-ia-se-d%C3%A9mocratise-pour-le-bien-ou-le-pire
- https://medvasc.info/1921-la-m%C3%A9decine-du-futur
- https://medvasc.info/1815-au-fond-de-l-oeil
- https://medvasc.info/1616-apprendre-l-art-et-la-science-du-diagnostic
- https://medvasc.info/1523-l-ia-diagnostique-la-tvp
- https://medvasc.info/1499-fast-track-14-biblio-ath%C3%A9rothrombose
- https://medvasc.info/1334-ia-et-risque-cardio-vasculaire
- https://medvasc.info/1290-embolie-pulmonaire-et-ml
- https://medvasc.info/1191-4-questions-sur-l-ia
- https://medvasc.info/542-intelligents-peut-%C3%AAtre,-artificiels-surement-2
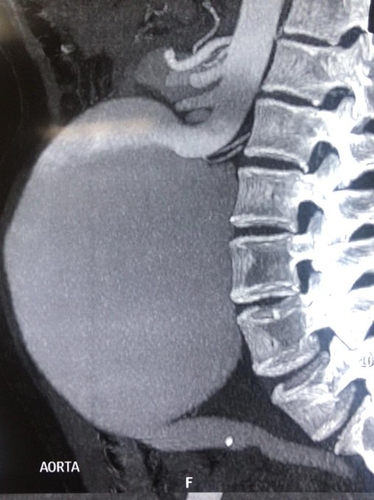


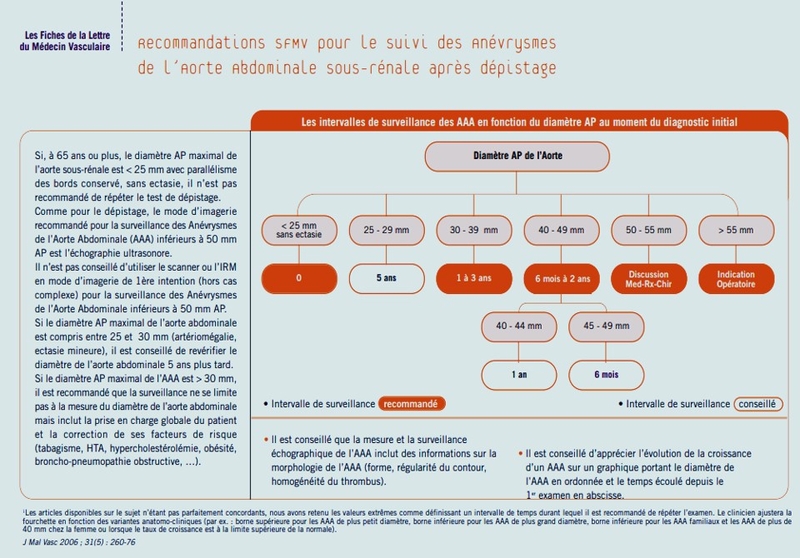
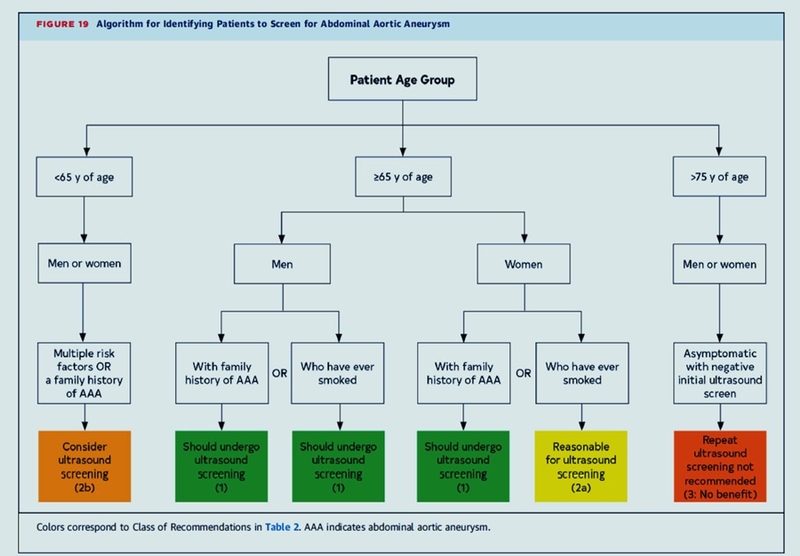
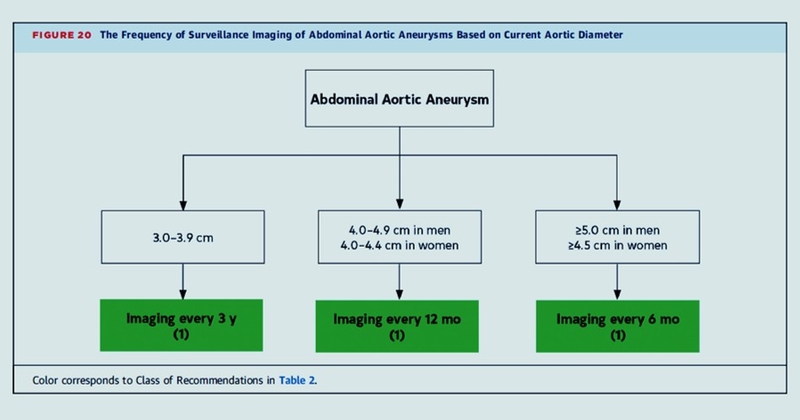
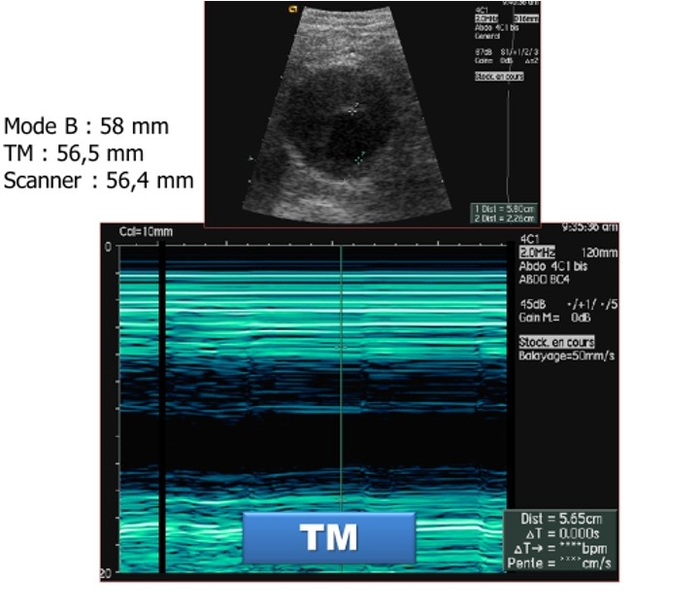
 Seuil de dépistage > 65 ans HOMMES et FEMMES y compris en cas d'atcds familiaux au 1° degré.
Seuil de dépistage > 65 ans HOMMES et FEMMES y compris en cas d'atcds familiaux au 1° degré.